K8s 部署指南
快速入门
通过 Minikube 快速体验 Kubernetes 系统。
系统安装
要部署 Kubenetes 系统,操作系统优先选择 CentOS 7 和 Ubuntu Server 版本。下面简单叙述系统安装流程。
安装 CentOS
先按照以下步骤来制作 CentOS 启动 U 盘:
- 从网易镜像站点下载 CentOS 7.9 x64 镜像文件 CentOS-7-x86_64-DVD-2009.iso。
- 从 GitHub 上下载 CentOS 启动 U 盘制作工具。下载完成后,安装并打开 Fedora Media Writer。
- 在 Fedora Media Writer 中,选择自定义镜像,并选择要写入的 U 盘。
- 使用 Fedora Media Writer 或其他 U 盘制作工具重新初始化 U 盘,使其成为 CentOS 启动 U 盘。
再按照下面步骤进行 CentOS 的安装:
- 将 U 盘插入主机,并启动进入 BIOS 设置界面。选择 UEFI 优先作为引导方式,并将 U 盘设置为第一引导设备。
- 在安装选择界面上选择 “Install CentOS 7”。
- 在安装信息摘要页面上,选择系统安装位置并进行硬盘分区:
- 选择手动配置分区,然后点击 “完成”。
- 点击 “自动创建挂载点”,然后删除
/home和swap挂载点,并将剩余容量添加到根目录/下。 - 点击 “开始安装”。
- 设置 root 密码,并等待安装完成。
安装 Ubuntu
Ubuntu 有分为 Desktop 和 Server 两个版本,其中 Server 版本对硬件兼容性较好且更新支持时间长。如果硬件兼容性较差,或者需要图形界面,可以选择 Desktop 版本。
安装 Ubuntu 22.04.2 Server 的步骤:
-
首先从官网下载 Ubuntu 22.04.2 Server 镜像,并使用 balenaEtcher 将其烧录到 U 盘。
-
在安装 Ubuntu Server 版本时,分区步骤非常复杂。如果不打算安装双系统,建议在 PE 环境下使用 DiskGenius 工具删除目标磁盘上的所有分区,然后再进行安装。
-
安装时大概率会碰到显卡驱动缺失问题,安装时或安装后可能会出现黑屏情况。可以在 grub 启动界面按下
e键进行编辑,在Linux那行的末尾添加参数nomodeset,然后按下Ctrl+X进行启动。 -
成功启动系统后,可以通过远程连接的方式修改 grub 配置。在
/etc/default/grub文件中找到GRUB_CMDLINE_LINUX_DEFAULT。在后面添加参数nomodeset,然后更新 grub:sudo vi /etc/default/grub sudo update-grub这样,在启动系统后就不会再出现黑屏问题了。
-
在安装过程中,对于没有明确说明的选项,一律选择
done或continue进入下一步。安装步骤如下:- 用 U 盘引导启动后,选择安装系统。
- 修改网卡的 IP 为静态,配置好 IP 地址。
- 将系统安装到整个磁盘上,并将挂载点
/的大小调整为最大,文件系统格式选择 xfs。 - 配置用户名为
assassing,主机名为ubuntu22。 - 选择安装 SSH 服务。
- 等待安装完成后重新启动系统。
虚拟机安装
如果在虚拟机进行系统安装,可以省略掉制作启动 U 盘的步骤,其他步骤基本一致。
在网络配置方面,可以使用桥接模式,让虚拟机同宿主机在一个子网下,虚拟机无需特别设置即可访问外网和局域网内其他主机。但要注意的是,国内网络运营商在光猫上对连接的客户端数量有限制,连接超过 5 个设备会随机选取设备断网。如果同时开了很多台虚拟机,会出现部分虚拟机网络不正常,部分又正常的情况。
行之有效的解决方法有三个:
- 找运营商上门技术支持,将限制去除。或者用自己的设备替代运营商送的光猫,作为拨号连接设备。这可能需要很多扯皮。
- 在光猫后接一个自己的路由器,客户端都接到路由器上。路由器和光猫不是一个网段,在光猫上只能看到路由器一个客户端,自然不存在限制。
- 不使用桥接网络模式,采用 NAT 模式来转发虚拟机流量。
如果采用 NAT 网络模式,还需要对网络进行手动配置。下面以配置成 192.168.1.0.24 网段为例:
- 将 NAT 网段设为 192.168.1.0/24,网关设为 192.168.1.1。
- 将 NAT 虚拟网卡(VM 中默认名 VMnet8)的 IP 设为 192.168.1.100,子网掩码 255.255.255.0,网关地址 192.168.1.1。
- 将能通外网的真实网卡属性配置成共享式,选择 NAT 虚拟网卡,这样虚拟机也能连通外网。
- 还可以配置 NAT 端口转发,例如将虚拟机的端口 22 转发到宿主机 10101 端口上,这样外部服务器可以用 ssh 通过宿主机 IP 地址加上 10101 端口连接虚拟机。
Docker 基础
首先需要在主机上安装好 Docker,然后创建一个简单的 Node.js 镜像并运行。
安装 Docker
安装 Docker-CE 20.10.10 版本参考步骤如下:
[root@k8s-101 ~]# yum install -y yum-utils
[root@k8s-101 ~]# yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
[root@k8s-101 ~]# yum makecache fast
[root@k8s-101 ~]# yum install -y docker-ce-20.10.10 docker-ce-cli-20.10.10 containerd.io docker-compose在 Ubuntu 中安装命令如下:
root@ubuntu22:~# curl -fsSL http://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
root@ubuntu22:~# add-apt-repository -y "deb [arch=amd64] http://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"
root@ubuntu22:~# apt install -y docker-ce=5:20.10.17~3-0~ubuntu-jammy docker-ce-cli=5:20.10.17~3-0~ubuntu-jammy containerd.io docker-compose配置 Docker
通过新增配置文件 /etc/docker/daemon.json 来设置 Docker 参数:
[root@k8s-101 ~]# mkdir /etc/docker/ ; tee /etc/docker/daemon.json <<-'EOF'
{
"exec-opts": [
"native.cgroupdriver=systemd"
],
"log-driver": "json-file",
"log-opts": {
"max-size": "10m",
"max-file": "3"
},
"registry-mirrors": [
"http://192.168.1.253:10007",
"https://docker.nju.edu.cn",
"https://registry.cn-hangzhou.aliyuncs.com",
"https://registry.cn-shanghai.aliyuncs.com",
"https://registry.cn-qingdao.aliyuncs.com",
"https://registry.cn-beijing.aliyuncs.com",
"https://registry.cn-zhangjiakou.aliyuncs.com",
"https://registry.cn-huhehaote.aliyuncs.com",
"https://registry.cn-wulanchabu.aliyuncs.com",
"https://registry.cn-shenzhen.aliyuncs.com",
"https://registry.cn-heyuan.aliyuncs.com",
"https://registry.cn-guangzhou.aliyuncs.com",
"https://registry.cn-chengdu.aliyuncs.com",
"https://mirror.ccs.tencentyun.com",
"https://dockerhub.azk8s.com",
"https://hub-mirror.c.163.com",
"https://mirror.sjtu.edu.cn",
"https://f1361db2.m.daocloud.io",
"https://registry.cn-hongkong.aliyuncs.com",
"https://registry.ap-northeast-1.aliyuncs.com",
"https://registry.ap-southeast-1.aliyuncs.com",
"https://registry.ap-southeast-2.aliyuncs.com",
"https://registry.ap-southeast-3.aliyuncs.com",
"https://registry.ap-southeast-5.aliyuncs.com",
"https://registry.ap-south-1.aliyuncs.com",
"https://registry.eu-central-1.aliyuncs.com",
"https://registry.eu-west-1.aliyuncs.com",
"https://registry.us-west-1.aliyuncs.com",
"https://registry.us-east-1.aliyuncs.com",
"https://registry.me-east-1.aliyuncs.com"
],
"insecure-registries": [
"192.168.1.253:10007",
"192.168.1.253:10008"
]
}
EOF配置参数的解释如下:
exec-opts:设置 cgroup 驱动方式,与 Kubernetes 中 kubelet 使用的方式匹配。log-driver、log-opts:设置 Docker 容器的日志格式和限制,日志文件最大为 10M,最多保留 3 个文件,以避免容器日志过大占用硬盘空间。registry-mirrors:镜像仓库地址。Docker 官方仓库地址已被屏蔽,不得已加入一大堆备用镜像仓库地址。insecure-registries:设置私有仓库地址,忽略对强制 HTTPS 认证的要求。
启动 Docker
配置完毕后,启动并设置 Docker 自启动:
[root@k8s-101 ~]# systemctl daemon-reload
[root@k8s-101 ~]# systemctl enable --now docker
Created symlink from /etc/systemd/system/multi-user.target.wants/docker.service to /usr/lib/systemd/system/docker.service.
[root@k8s-101 ~]# docker -v
Docker version 20.10.10, build b485636
[root@k8s-101 ~]# docker-compose -v
docker-compose version 1.18.0, build 8dd22a9创建 Node.js 应用
创建一个简单的 Node.js Web 应用,并打包成容器镜像。应用会接受 HTTP 请求并响应应用运行的主机名。
新建一个 app.js 文件,内容如下:
[root@centos7 ~]# vi app.js
const http = require('http');
const os = require('os');
console.log("Runing...");
var handle = function(request, response){
console.log("Request IP: " + request.connection.remoteAddress);
response.writeHead(200);
response.end("Hostname: " + os.hostname() + "\n");
};
var www = http.createServer(handle);
www.listen(8080);应用在 8080 端口启动一个 HTTP 服务器,服务器会以状态码 200 和输出消息来响应每个请求。请求处理程序会将客户端 IP 打印到标准输出。
创建 Dockerfile
Dockerfile 文件需要和 app.js 文件放在同一目录,内容如下:
[root@centos7 ~]# vi Dockerfile
FROM node:7
ADD app.js /app.js
ENTRYPOINT ["node", "app.js"]这里使用 Node 7 版本的基础镜像,然后将 app.js 文件添加到镜像根目录,最后执行 node app.js 命令。
构建容器镜像
构建不是由 Docker 客户端进行的,而是将整个目录的文件上传到 Docker 守护进程并在那里进行。因此,在守护进程运行在另外一个服务器时,不要在构建目录中包含不需要的文件。
使用 docker build 构建名为 kubia 的镜像:
[root@centos7 ~]# docker build -t kubia .
Sending build context to Docker daemon 14.34kB
Step 1/3 : FROM node:7
---> d9aed20b68a4
Step 2/3 : ADD app.js /app.js
---> aa745953f3ae
Step 3/3 : ENTRYPOINT ["node", "app.js"]
---> Running in 76a3951dc11c
Removing intermediate container 76a3951dc11c
---> cdd0c7614e03
Successfully built cdd0c7614e03
Successfully tagged kubia:latestDockerfile 中每一条指令都会创建一个新层。上面的例子中,有一层用来添加 app.js,另外一层运行 node app.js 命令,最后一层会被标记为 kubia:latest。构建完成后镜像会存储在本地。
[root@centos7 ~]# docker images kubia
REPOSITORY TAG IMAGE ID CREATED SIZE
kubia latest cdd0c7614e03 30 seconds ago 660MB运行容器镜像
指定容器名为 kubia-container,暴露端口 8080,在后台运行:
[root@centos7 ~]# docker run --name kubia-container -p 8080:8080 -d kubia
c971ba30949f2b1dbca90a96274a3a06a577d33f981e9bc82f327fbdb7010277启动后在浏览器通过 8080 端口访问服务:
[root@centos7 ~]# curl 127.0.0.1:8080
Hostname: f4c9088f3b28此时容器主机名就是 Docker 容器短 ID。可以查询容器日志:
[root@centos7 ~]# docker logs kubia-container
Runing...
Request IP: ::ffff:192.168.2.101
Request IP: ::ffff:192.168.2.205搭建 Minikube
Minikube 是一个构建单节点集群的工具,具体使用可以参考:GitHub
安装
下面通过下载 RPM 包的方式安装 Minikube:
[root@centos7 ~]# curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-latest.x86_64.rpm
[root@centos7 ~]# rpm -Uvh minikube-latest.x86_64.rpm还需要安装 Kubectl 客户端来与 Minikube 进行交互:
[root@centos7 ~]# curl -LO https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl
[root@centos7 ~]# chmod +x ./kubectl && mv ./kubectl /usr/local/bin/kubectl启动
如果不带参数启动,会报错说不能使用 root 权限运行。这里使用一个加入了 docker 组的 user1 来运行。
另外经常会碰到镜像拉取失败的情况,可以加入 --image-mirror-country=cn --image-repository=registry.cn-hangzhou.aliyuncs.com/google_containers 参数指定镜像仓库:
[root@server6 ~]$ useradd -G docker user1
[root@server6 ~]$ su -l user1
[user1@server6 ~]$ minikube start
* minikube v1.23.2 on Centos 7.9.2009
* Automatically selected the docker driver
* Using image repository registry.cn-hangzhou.aliyuncs.com/google_containers
* Starting control plane node minikube in cluster minikube
* Pulling base image ...
* Creating docker container (CPUs=2, Memory=2200MB) ...
* Verifying Kubernetes components...
* Enabled addons: storage-provisioner, default-storageclass
* kubectl not found. If you need it, try: 'minikube kubectl -- get pods -A'
* Done! kubectl is now configured to use "minikube" cluster and "default" namespace by default遇到其他报错可以删除文件后,重新运行启动命令:
[user1@server6 ~]$ minikube delete
* Deleting "minikube" in docker ...
* Removed all traces of the "minikube" cluster.
[user1@server6 ~]$ rm -rf .minikube查看
安装好以后可以使用 kubectl 命令查看集群工作状态:
[user1@server6 ~]$ kubectl cluster-info
Kubernetes control plane is running at https://192.168.49.2:8443
CoreDNS is running at https://192.168.49.2:8443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
[user1@server6 ~]$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
minikube Ready control-plane,master 8m40s v1.22.2
[user1@server6 ~]$ kubectl describe node minikube
Name: minikube
Roles: control-plane,master
...建立 Pod
使用 kubectl run 命令可以创建所有必要组件而无需使用 JSON 或 YAML 文件。其中使用 --image 指定镜像,使用 --port 说明容器监听端口:
[user1@server6 ~]$ kubectl run kubia --image=assassing/kubia --port=8080
pod/kubia created不能用 kubectl 直接列出容器,因为 Pod 才是操作对象。一个 Pod 包含一个或多个容器,每个容器都运行一个应用进程,它们总是运行在同一个工作节点及命名空间中。查看 Pod 运行状态:
[user1@server6 ~]$ kubectl get pod
NAME READY STATUS RESTARTS AGE
kubia 1/1 Running 0 58s暴露端口
每个 Pod 都有自己的 IP,Pod 分布在不同的工作节点上。它们不能被外部访问,需要通过服务对象来公开:
[user1@server6 ~]$ kubectl expose pod kubia --type=NodePort
service/kubia exposed
[user1@server6 ~]$ minikube service kubia --url
http://192.168.49.2:32556
[user1@server6 ~]$ kubectl expose pod kubia --type=LoadBalancer --name kubia-http
service/kubia-http exposed查看刚刚新建的服务:
[user1@server6 ~]$ kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 42m
kubia NodePort 10.107.120.56 <none> 8080:32556/TCP 3m22s
kubia-http LoadBalancer 10.108.108.14 <pending> 8080:31003/TCP 56s显示 pending 是因为 Minikube 不支持 LoadBalancer 类型的服务,可以用另外一个命令查看:
[user1@server6 ~]$ minikube service kubia-http
|-----------|------------|-------------|---------------------------|
| NAMESPACE | NAME | TARGET PORT | URL |
|-----------|------------|-------------|---------------------------|
| default | kubia-http | 8080 | http://192.168.49.2:31003 |
|-----------|------------|-------------|---------------------------|
* Opening service default/kubia-http in default browser...切换回 root 账号,试着访问一下:
[root@centos7 ~]# curl http://192.168.49.2:31401
Hostname: kubia
[root@centos7 ~]# curl http://192.168.49.2:32050
Hostname: kubia系统配置
主要以 CentOS 7 系统作为例子。其他发行版在安装工具步骤和自带工具使用上可能有差别,只要达成目标即可。
修改 IP 地址
安装完系统之后,第一件事就是修改好 IP 地址,然后通过 ssh 远程来连接系统。
CentOS
要修改 IP 地址可通过 nmcli 命令,或者修改 /etc/sysconfig/network-scripts/ 下面的网卡配置文件都可:
[root@localhost ~]# nmcli connection modify ens32 connection.autoconnect yes ipv4.method manual ipv4.addresses 192.168.1.101/24 ipv4.gateway 192.168.1.1 ipv4.dns 8.8.8.8
[root@localhost ~]# nmcli connection up ens32
[root@localhost ~]# nmcli
ens32: connected to ens32
"Intel 82545EM"
ethernet (e1000), 00:0C:29:DB:DA:56, hw, mtu 1500
ip4 default, ip6 default
inet4 192.168.1.101/24
route4 192.168.1.0/24
route4 0.0.0.0/0
inet6 240e:383:419:201:f417:1a97:df8f:9932/64
inet6 fe80::5f5c:196b:8e66:a650/64
route6 fe80::/64上面修改网卡 ens32 的 IP 地址为 192.168.1.101,网关地址 192.168.1.1,DNS 地址 8.8.8.8。并立即生效。
Ubuntu
Ubuntu 中默认不带 nmcli ,可以通过修改配置文件 /etc/netplan/00-installer-config.yaml 来修改网卡配置:
assassing@ubuntu22:~$ sudo vi /etc/netplan/00-installer-config.yaml
assassing@ubuntu22:~$ sudo netplan apply设置 DNS 服务器地址:
root@ubuntu22:~# sed -i "s/#DNS=/DNS=8.8.8.8 114.114.114.114/g" /etc/systemd/resolved.conf
root@ubuntu22:~# systemctl restart systemd-resolved账户配置
如果对操作系统不熟练,不建议使用 root 账户作为日常用户。下面是配置使用 root 账户的方法。
阿里云
刚刚开通的阿里云服务器,无法通过 ssh 直接连接。可以通过阿里云管理平台,点击远程连接,选择发送命令来配置主机。
例如修改 ssh 默认端口由 22 改为 2222,并允许使用账号密码登录。重启 sshd 服务来生效:
#!/bin/bash
sed -i "s/#Port 22/Port 2222/g" /etc/ssh/sshd_config
sed -i "s/PasswordAuthentication no/PasswordAuthentication yes/g" /etc/ssh/sshd_config
systemctl restart sshd通过发送脚本的方式修改 root 账号密码:
#!/bin/bash
echo "qv4YB7#x9WhPj?i4E1DRgu1dlOWR" | passwd root --stdin > /dev/null 2>&1添加用户 alice 并设置密码。密码是 /etc/shadow 中哈希值:
#!/bin/bash
useradd -p \$6\$YVLnCcQL\$NlbdFMzHHzw9Byk2EFjl4BNCm0riq22HnJKTVcccZv/FQ/Y2HgvSeavPCUbdgzTmA3T3ksn7SYkq96An12oBW0 alice最后要记得调整安全组策略。在云服务器 ECS 的安全组中,为自定义的 sshd 端口 2222 设置白名单,这样才能使用 ssh 远程连接。
Ubuntu
在 Ubuntu 中,默认情况下是没有开启 root 用户登录。首先需要使用普通用户登录,并设置 root 账号的密码:
assassing@ubuntu22:~$ sudo passwd root
New password:
Retype new password:
passwd: password updated successfully
assassing@ubuntu22:~$ su -l
Password:
root@ubuntu22:~# 然后,修改 SSH 服务的配置文件,允许 root 用户使用 SSH 连接:
root@ubuntu22:~# sed -i "s/#PermitRootLogin prohibit-password/PasswordAuthentication yes/g" /etc/ssh/sshd_config
root@ubuntu22:~# sed -i '85a\PermitRootLogin yes' /etc/ssh/sshd_config
root@ubuntu22:~# systemctl restart sshd现在可以使用 root 用户直接连接到 22 端口,并删除普通用户 “assassing”:
root@ubuntu22:~# userdel -r assassing登录限制
可以设置一台服务器作为跳板机,只能通过它连接其他服务器。
主节点
跳板机 ssh 连接端口是 2222,修改 sshd 配置来禁止 root 用户登录。只能通过 普通 用户登录:
[root@k8s-s1 ~]# sed -i "s/PermitRootLogin yes/PermitRootLogin no/g" /etc/ssh/sshd_config
[root@k8s-s1 ~]# systemctl restart sshd安装 Fail2ban 来阻止恶意登录:
[root@k8s-m1-pro ~]# yum install -y fail2ban修改配置启用通过 iptables 防护非法 sshd 登录。规则为在 300 秒内输错 5 次密码,IP 被禁止连接 2222 端口 1 个小时:
[root@k8s-m1-pro ~]# vi /etc/fail2ban/jail.conf
...
[sshd]
# To use more aggressive sshd modes set filter parameter "mode" in jail.local:
# normal (default), ddos, extra or aggressive (combines all).
# See "tests/files/logs/sshd" or "filter.d/sshd.conf" for usage example and details.
#mode = normal
enabled = true
filter = sshd
port = 2222
action = iptables[name=SSH, port=2222, protocol=tcp]
logpath = %(sshd_log)s
backend = %(sshd_backend)s
bantime = 3600
findtime = 300
maxretry = 5
...启动服务:
[root@k8s-m1-pro fail2ban]# systemctl enable --now fail2ban如果需要限制 Nginx 访问可以参考:知乎专栏
其他节点
除了跳板机外,修改系统 /etc/hosts.deny 和 /etc/hosts.allow 文件内容,只允许通过内网 ssh 连接,其他地址拒绝:
[root@k8s-w2-pro ~]# echo "sshd:ALL:deny" >> /etc/hosts.deny
[root@k8s-w2-pro ~]# echo "sshd:172.16.0.0/255.255.0.0:allow" >> /etc/hosts.allow
[root@k8s-w2-pro ~]# systemctl restart sshd查询异常登录
/var/log/secure 文件记录有异常登录信息:
[root@k8s-m1-pro ~]# tail -n 30 /var/log/secure在跳板机上可以通过 fail2ban-client 命令查看被 ban 列表:
[root@k8s-m1-pro fail2ban]# fail2ban-client status
[root@k8s-m1-pro fail2ban]# fail2ban-client status sshd
[root@k8s-m1-pro fail2ban]# iptables -nvL解除被 ban 的 IP 地址操作:
[root@k8s-m1-pro fail2ban]# fail2ban-client set sshd unbanip 47.101.138.100镜像仓库
修改 yum 仓库地址为阿里云镜像仓库,提升软件安装和更新速度:
[root@localhost ~]# yum install -y wget
[root@localhost ~]# mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
[root@localhost ~]# mv /etc/yum.repos.d/epel.repo /etc/yum.repos.d/epel.repo.backup
[root@localhost ~]# mv /etc/yum.repos.d/epel-testing.repo /etc/yum.repos.d/epel-testing.repo.backup
[root@localhost ~]# cd /etc/yum.repos.d/ && wget http://mirrors.aliyun.com/repo/Centos-7.repo && wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo && cd -
[root@localhost ~]# yum clean all
[root@localhost ~]# yum makecache虽然阿里云镜像仓库下载速度被限制成 500 kB/s,但胜在稳定。
内核升级
CentOS 7 安装镜像自带的 3.10 内核已太旧,很多应用需要的内核功能支持不了。装好后第一时间升级内核。
查看内核
查看当前运行的内核版本:
[root@localhost ~]# uname -sr
Linux 3.10.0-1160.el7.x86_64安装内核
导入 ELRepo 软件仓库的公共秘钥,安装 yum 源:
[root@localhost ~]# rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
[root@localhost ~]# yum install -y https://www.elrepo.org/elrepo-release-7.el7.elrepo.noarch.rpm列出当前最新内核版本:
[root@localhost ~]# yum --disablerepo="*" --enablerepo="elrepo-kernel" list available
Available Packages
kernel-lt.x86_64 5.4.242-1.el7.elrepo elrepo-kernel
kernel-ml-devel.x86 5.4.242-1.el7.elrepo elrepo-kernel
kernel-ml.x86_64 6.3.2-1.el7.elrepo elrepo-kernel其中 kernel-lt 表示 long-term(长期支持版本),kernel-ml 表示 latest mainline(最新主线版本)。选择安装 kernel-lt.x86_64 版本。
[root@localhost ~]# yum install -y kernel-lt-5.4.242-1.el7.elrepo --enablerepo=elrepo-kernel修改引导
查看已安装系统内核。正常情况下会保留旧内核,升级失败时可以回滚:
[root@localhost ~]# awk -F\' '$1=="menuentry " {print i++ " : " $2}' /etc/grub2.cfg
0 : CentOS Linux (5.4.242-1.el7.elrepo.x86_64) 7 (Core)
1 : CentOS Linux (3.10.0-1160.el7.x86_64) 7 (Core)
2 : CentOS Linux (0-rescue-e175a587657a4fae8ab45bb178e24c22) 7 (Core)如果引导方式是 UEFI,则需要查看 /etc/grub2-efi.cfg 文件:
[root@localhost ~]# awk -F\' '$1=="menuentry " {print i++ " : " $2}' /etc/grub2-efi.cfg设置内核启动顺序,需要重新生成引导文件:
[root@localhost ~]# grub2-set-default 0
[root@localhost ~]# grub2-mkconfig -o /boot/grub2/grub.cfg
Generating grub configuration file ...
Found linux image: /boot/vmlinuz-5.4.242-1.el7.elrepo.x86_64
Found initrd image: /boot/initramfs-5.4.242-1.el7.elrepo.x86_64.img
Found linux image: /boot/vmlinuz-3.10.0-1160.el7.x86_64
Found initrd image: /boot/initramfs-3.10.0-1160.el7.x86_64.img
Found linux image: /boot/vmlinuz-0-rescue-e175a587657a4fae8ab45bb178e24c22
Found initrd image: /boot/initramfs-0-rescue-e175a587657a4fae8ab45bb178e24c22.img
doneUEFI 启动配置文件位置的位置不同:
[root@localhost ~]# grub2-set-default 0
[root@localhost ~]# grub2-mkconfig -o /boot/efi/EFI/centos/grub.cfg降级内核
内核降级和升级步骤一样,用 yum 安装指定内核版本后,修改引导配置文件并重启。
删除内核
重启后如果新内核运作正常,可以删除旧内核:
[root@localhost ~]# yum remove -y kernel-lt-3.10.0-1160.el7.elrepo.x86_64驱动问题
如果旧网卡驱动识别不了,需要手动载入驱动:
[root@k8s-250 ~]# rmmod r8169 && modprobe r8169 && systemctl restart network设置为系统启动服务:
[root@k8s-250 /]# tee /etc/systemd/system/load-realtek-driver.service<<EOF
[Unit]
Description=Load Realtek drivers.
Before=network-online.target
[Service]
Type=simple
ExecStartPre=/usr/sbin/rmmod r8169
ExecStart=/usr/sbin/modprobe r8169
[Install]
WantedBy=multi-user.target
EOF
[root@k8s-250 /]# systemctl enable load-realtek-driver.service内核功能调整
需要修改内核参数,否则安装运行 K8s 会失败.
禁用虚拟内存
虽然安装系统时已经去除了 swap 分区,但保险起见,还是对开机挂载配置文件 /etc/fstab 进行重写。然后重新挂载根目录:
[root@localhost ~]# swapoff -a
[root@localhost ~]# yes | cp /etc/fstab /etc/fstab_bak
[root@localhost ~]# cat /etc/fstab_bak |grep -v swap > /etc/fstab
[root@localhost ~]# mount -n -o remount,rw /
[root@localhost ~]# echo "vm.swappiness = 0" >> /etc/sysctl.conf开启端口转发
首先要确认网卡 MAC 地址没有冲突,然后确保 br_netfilter 和 overlay 模块被加载:
[root@localhost ~]# echo "br_netfilter" >> /etc/modules-load.d/k8s.conf
[root@localhost ~]# echo "overlay" >> /etc/modules-load.d/k8s.conf
[root@localhost ~]# modprobe br_netfilter
[root@localhost ~]# modprobe overlay
[root@localhost ~]# lsmod | grep 'br_netfilter\|overlay'
br_netfilter 28672 0
overlay 114688 35
[root@localhost ~]# modprobe ip_vs
[root@localhost ~]# modprobe ip_vs_rr
[root@localhost ~]# modprobe ip_vs_wrr
[root@localhost ~]# modprobe ip_vs_sh
[root@localhost ~]# echo "net.ipv4.ip_forward = 1" >> /etc/sysctl.conf
[root@localhost ~]# echo "net.ipv4.ip_nonlocal_bind = 1" >> /etc/sysctl.conf
[root@localhost ~]# echo "net.ipv4.ip_local_port_range = 1024 65535" >> /etc/sysctl.conf
[root@localhost ~]# echo "net.bridge.bridge-nf-call-ip6tables = 1" >> /etc/sysctl.conf
[root@localhost ~]# echo "net.bridge.bridge-nf-call-iptables = 1" >> /etc/sysctl.conf
[root@localhost ~]# echo "net.core.rmem_max=2500000" >> /etc/sysctl.conf
[root@localhost ~]# echo "10000 65535" > /proc/sys/net/ipv4/ip_local_port_range去除文件系统限制
根据硬件情况,对文件系统限制调大。最后使用 sysctl --system 命令来使配置生效:
[root@localhost ~]# ulimit -SHn 65536
[root@localhost ~]# echo "* soft nofile 655350" >> /etc/security/limits.conf
[root@localhost ~]# echo "* hard nofile 655350" >> /etc/security/limits.conf
[root@localhost ~]# echo "vm.max_map_count = 524288" >> /etc/sysctl.conf
[root@localhost ~]# echo "fs.file-max = 655350" >> /etc/sysctl.conf
[root@localhost ~]# echo "fs.inotify.max_user_instances=8192" >> /etc/sysctl.conf
[root@localhost ~]# sysctl --system关闭防火墙
关闭防火墙和 SELinux,否则容器访问主机文件系统会不正常:
[root@localhost ~]# service iptables stop
[root@localhost ~]# chkconfig iptables off
[root@localhost ~]# systemctl stop firewalld
[root@localhost ~]# systemctl disable firewalld
[root@localhost ~]# setenforce 0
[root@localhost ~]# sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config
[root@localhost ~]# getenforce #个性化设置
一些按照喜好来设置的系统调整。
修改系统语言
修改系统语言为英语:
[root@localhost ~]# echo 'LANG="en_US.UTF-8"' > /etc/locale.conf修改主机名
修改节点上的主机名,例如 k8s-master-1、k8s-m1-pro、k8s-250 等,尽量取有意义的名字:
[root@localhost ~]# hostnamectl set-hostname k8s-101将主机名添加到本地域名解析 /etc/hosts 文件中:
[root@localhost ~]# echo "127.0.0.1 $(hostname)" >> /etc/hosts时间同步
设置网络时间同步。若服务器时间不对,可能会遇到一些莫名其妙的验证方面问题:
[root@localhost ~]# timedatectl set-timezone "Asia/Shanghai"
[root@localhost ~]# yum -y install ntp ntpdate
[root@localhost ~]# ntpdate cn.pool.ntp.org
[root@localhost ~]# hwclock --systohc
[root@localhost ~]# hwclock -w
[root@localhost ~]# date安装工具
安装一些常用系统维护工具:
[root@localhost ~]# yum install -y git wget net-tools bind-utils vim bash-completion nfs-utils jq nc telnet lvm2 unzip iftop lsofUbuntu 中 bind-utils 替换为 bind9-utils,nfs-utils 替换为 nfs-kernel-server,nc 已经自带。安装命令改为这样:
root@ubuntu22:~# apt-get update
root@ubuntu22:~# apt install -y git wget net-tools bind9-utils vim bash-completion jq telnet lvm2 nfs-kernel-server限制日志大小
限制系统 journal 日志保留时常为 1 周,免得磁盘被大量日志挤占空间:
[root@localhost ~]# journalctl --vacuum-time=1w设置变量
修改 /etc/profile 文件,添加一些常用变量:
[root@localhost ~]# echo "export HISTTIMEFORMAT='`whoami` : %F %T :'" >> /etc/profile
[root@localhost ~]# echo "export NFS_SERVER=192.168.1.253" >> /etc/profileNFS 服务器地址变量按实际情况填写。
免密登录
可以在特定服务器上设置免密登录别的服务器:
[root@k8s-250 ~]# ssh-keygen
[root@k8s-250 ~]# ssh-copy-id root@192.168.1.248编辑器配置
在 Ubuntu 中,vi 需要设置粘贴模式,禁止粘贴文本时,可能会出现自动缩进或添加额外的空格和制表符的情况:
root@ubuntu22:~# echo "set paste" >> /etc/vim/vimrc 磁盘管理
一般建议把容器工作目录和数据储存同系统根目录分开挂载,免得影响系统运行稳定性。下面以新增一块储存盘为例,演示磁盘管理操作。
初始化
服务器上新增一块固态硬盘 sdb,需要初始化后才能使用:
[root@k8s-master ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 223.6G 0 disk
├─sda1 8:1 0 200M 0 part /boot/efi
├─sda2 8:2 0 1G 0 part /boot
└─sda3 8:3 0 222.4G 0 part
└─centos-root 253:0 0 222.4G 0 lvm /
sdb 8:16 0 931.5G 0 disk 使用 fdisk 命令来管理磁盘:
[root@k8s-master ~]# fdisk /dev/sdb
Welcome to fdisk (util-linux 2.23.2).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Device does not contain a recognized partition table
Building a new DOS disklabel with disk identifier 0x50398e42.
Command (m for help): p
Disk /dev/sdb: 1000.2 GB, 1000204886016 bytes, 1953525168 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x50398e42
Device Boot Start End Blocks Id System先使用初始化并分区:
Command (m for help): n
Partition type:
p primary (0 primary, 0 extended, 4 free)
e extended
Select (default p): p
Partition number (1-4, default 1):
First sector (2048-1953525167, default 2048):
Using default value 2048
Last sector, +sectors or +size{K,M,G} (2048-1953525167, default 1953525167):
Using default value 1953525167
Partition 1 of type Linux and of size 931.5 GiB is set修改分区 system ID 为 lvm :
Command (m for help): t
Selected partition 1
Hex code (type L to list all codes): 8e
Changed type of partition 'Linux' to 'Linux LVM'
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
Syncing disks.
[root@k8s-master ~]# partprobe创建 PV
使用 pvcreate 命令来创建 PV:
[root@k8s-103 ~]# pvcreate /dev/sdb1
Physical volume "/dev/sdb1" successfully created.
[root@k8s-103 ~]# pvscan
PV /dev/sda2 VG centos lvm2 [<49.00 GiB / 0 free]
PV /dev/sdb1 lvm2 [<200.00 GiB]
Total: 2 [<249.00 GiB] / in use: 1 [<49.00 GiB] / in no VG: 1 [<200.00 GiB]查询刚创建的 PV 详细信息:
[root@k8s-103 ~]# pvdisplay
--- Physical volume ---
PV Name /dev/sda2
VG Name centos
PV Size <49.00 GiB / not usable 3.00 MiB
Allocatable yes (but full)
PE Size 4.00 MiB
Total PE 12543
Free PE 0
Allocated PE 12543
PV UUID FOgL5t-v6EE-neHA-Kdpy-ynt0-yzXr-Tin7Am
"/dev/sdb1" is a new physical volume of "<200.00 GiB"
--- NEW Physical volume ---
PV Name /dev/sdb1
VG Name
PV Size <200.00 GiB
Allocatable NO
PE Size 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID rxkppt-GxSK-igDI-NgI1-3CZw-F3r2-YtXIU9创建 VG
声明变量:
[root@k8s-103 ~]# export DIR=ssd新建 VG:
[root@k8s-103 ~]# vgcreate ${DIR} /dev/sdb1
Volume group "ssd" successfully created
[root@k8s-103 ~]# vgscan
Reading volume groups from cache.
Found volume group "centos" using metadata type lvm2
Found volume group "ssd" using metadata type lvm2
[root@k8s-103 ~]# vgdisplay
--- Volume group ---
VG Name centos
System ID
Format lvm2
Metadata Areas 1
Metadata Sequence No 2
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 1
Open LV 1
Max PV 0
Cur PV 1
Act PV 1
VG Size <49.00 GiB
PE Size 4.00 MiB
Total PE 12543
Alloc PE / Size 12543 / <49.00 GiB
Free PE / Size 0 / 0
VG UUID xuRCcF-ROBb-5OhK-4BAY-fuBi-EvlU-uqxs9T
--- Volume group ---
VG Name ssd
System ID
Format lvm2
Metadata Areas 1
Metadata Sequence No 1
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 0
Open LV 0
Max PV 0
Cur PV 1
Act PV 1
VG Size <200.00 GiB
PE Size 4.00 MiB
Total PE 51199
Alloc PE / Size 0 / 0
Free PE / Size 51199 / <200.00 GiB
VG UUID yq6LIQ-D4Xm-hPGZ-2Zqi-Bdsc-vz3Y-cvuAmC创建 LV
建立名为 ssd 的 LV,使用参数 -l 指定分配 free PE 数量:
[root@k8s-103 ~]# lvcreate -l +100%FREE -n ${DIR} ${DIR}
Logical volume "ssd" created.
[root@k8s-103 ~]# lvdisplay
--- Logical volume ---
LV Path /dev/centos/root
LV Name root
VG Name centos
LV UUID GySaQs-a1ni-kiUg-Ys86-j287-Sqpu-9PWECL
LV Write Access read/write
LV Creation host, time localhost, 2023-05-17 08:02:19 +0800
LV Status available
# open 1
LV Size <49.00 GiB
Current LE 12543
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 8192
Block device 253:0
--- Logical volume ---
LV Path /dev/ssd/ssd
LV Name ssd
VG Name ssd
LV UUID EkAIWn-ad01-3nsX-cfBN-rpgV-dSwk-Pc1MJI
LV Write Access read/write
LV Creation host, time k8s-103, 2023-05-17 02:28:34 +0800
LV Status available
# open 0
LV Size <200.00 GiB
Current LE 51199
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 8192
Block device 253:1格式化
格式化成 xfs 格式,并挂载到指定目录下面:
[root@k8s-103 ~]# mkfs.xfs /dev/${DIR}/${DIR}
meta-data=/dev/ssd/ssd isize=512 agcount=4, agsize=13106944 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=52427776, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=25599, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0 extsz=4096 blocks=0, rtextents=0
[root@k8s-103 ~]# mkdir /${DIR}
[root@k8s-103 ~]# mount /dev/${DIR}/${DIR} /${DIR}/
[root@k8s-103 ~]# echo "/dev/mapper/${DIR}-${DIR} /${DIR} xfs defaults 0 0" >> /etc/fstab
[root@k8s-103 ~]# df -hT
Filesystem Type Size Used Avail Use% Mounted on
devtmpfs devtmpfs 3.9G 0 3.9G 0% /dev
tmpfs tmpfs 3.9G 0 3.9G 0% /dev/shm
tmpfs tmpfs 3.9G 9.0M 3.9G 1% /run
tmpfs tmpfs 3.9G 0 3.9G 0% /sys/fs/cgroup
/dev/mapper/centos-root xfs 49G 2.2G 47G 5% /
/dev/sda1 xfs 1014M 184M 831M 19% /boot
tmpfs tmpfs 793M 0 793M 0% /run/user/0
/dev/mapper/ssd-ssd xfs 200G 33M 200G 1% /ssd删除磁盘
删除磁盘则是逆序操作。下面使删除挂载卷例子:
[root@k8s-249 ~]# vi /etc/fstab
[root@k8s-249 ~]# umount /databases
[root@k8s-249 ~]# yes | lvremove /dev/databases/databases
[root@k8s-249 ~]# vgremove databases
[root@k8s-249 ~]# pvremove /dev/sdb1
[root@k8s-248 ~]# systemctl daemon-reload
[root@k8s-249 ~]# systemctl restart proc-fs-nfsd.mount重启
最后重启服务器,让改动生效:
[root@localhost ~]# reboot高可用集群部署
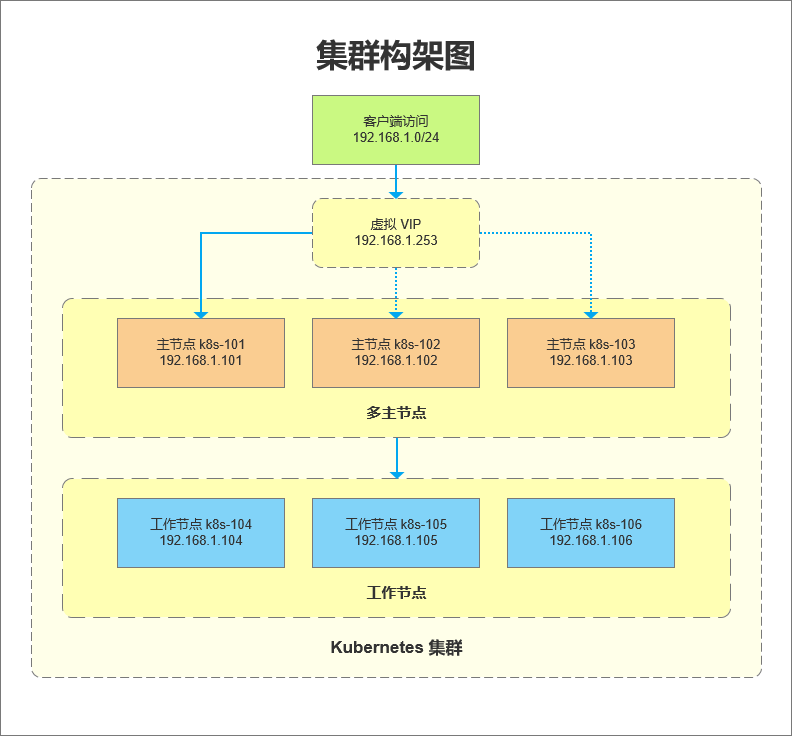
以部署三主节点高可用集群示例,系统为 CentOS 7,K8s 版本为 1.22.3。集群构架图如下:
Kubeadm
Kubeadm 是由志愿者开发的专门用于部署 K8s 的工具。自 K8s 1.14 版本以后,Kubeadm 项目已经正式宣布 GA(General Availability),可以在官方文档中查看详细的使用说明。
kubeadm init
初始化的大致过程如下:
- kubeadm 执行初始化检查。
- 生成 token 和证书。
- 生成 KubeConfig 文件,kubelet 需要使用该文件与 Master 进行通信。
- 安装 Master 组件,从镜像仓库下载组件和 Docker 镜像。
- 安装附加组件 kube-proxy 和 kube-dns。
- Kubernetes Master 初始化成功。
- 提示如何配置 kubectl,安装 pod 网络,以及其他节点注册到集群的方法。
执行 kubeadm init 指令后,kubeadm 首先会进行一系列的检查工作,以确定本机是否适用于部署 K8s。这一步的检查被称为 Preflight Checks,其主要目的是检查内核版本、CGroups 模块、kubelet 版本、网络端口等必要的配置是否正确。
默认情况下,与 API 服务器的通信必须使用 HTTPS 方式,因此需要证书文件。在完成系统检查后,kubeadm 开始生成 K8s 对外提供服务所需的各种证书和目录。kubeadm 生成的证书存放在主节点的 /etc/kubernetes/pki/ 目录下,其中最重要的文件是 ca.crt 和 ca.key。也可以将现有的证书复制到证书目录中,这样 kubeadm 就不会生成证书:
[root@k8s-250 ~]$ ls /etc/kubernetes/pki
apiserver.crt apiserver.key ca.crt front-proxy-ca.crt front-proxy-client.key
apiserver-etcd-client.crt apiserver-kubelet-client.crt ca.key front-proxy-ca.key sa.key
apiserver-etcd-client.key apiserver-kubelet-client.key etcd front-proxy-client.crt sa.pub生成证书之后,kubeadm 接下来会创建用于访问 API 服务器的配置文件,并存放在 /etc/kubernetes/ 目录下。这些文件记录了主节点的服务器地址、端口和证书位置等信息,客户端可以直接使用这些信息:
[root@k8s-250 ~]$ ls /etc/kubernetes/
admin.conf controller-manager.conf kubeadm-master.config kubelet.conf manifests pki scheduler.conf随后,kubeadm 会为 Master 组件生成 pod 的配置文件,并以静态 pod 的形式运行。这种容器启动的方式允许将要部署的 pod 的 YAML 文件放在一起,当 Kubelet 启动时,会自动加载这些文件并启动 pod。这些配置文件默认存放在 /etc/kubernetes/manifests/ 目录下:
[root@k8s-250 ~]$ ll /etc/kubernetes/manifests/
total 16
-rw------- 1 root root 2258 Apr 20 22:19 etcd.yaml
-rw------- 1 root root 3424 Apr 20 22:29 kube-apiserver.yaml
-rw------- 1 root root 2906 Apr 20 22:30 kube-controller-manager.yaml
-rw------- 1 root root 1492 Apr 20 22:30 kube-scheduler.yaml然后,kubeadm 会为集群生成一个用于加入集群的 bootstrap token。其他证书等信息通过 ConfigMap 的方式保存在 etcd 中。
最后是安装默认插件,包括 kube-proxy 和 DNS 插件,用于提供整个集群的服务发现和 DNS 功能。
kubeadm join
加入集群时,需要使用主节点初始化时生成的令牌(token),该令牌用于进行一次性身份验证。工作节点在获取 ConfigMap 中的证书后,将使用证书进行安全通信。
安装组件
kubelet 是唯一没有以容器形式运行的 K8s 组件,它通过 systemd 服务运行。kubeadm 用来创建 K8s 集群,kubectl 是用来执行 K8s 命令的工具。其他 K8s 的系统组件都以容器化运行,并被放到 kube-system namespaces 中,例如 coredns、etcd、apiserver、controller-manager。
在所有要加入 K8s 集群的主机中安装 kubelet、kubeadm 和 kubectl 1.22.3 版本:
[root@k8s-101 ~]# tee /etc/yum.repos.d/kubernetes.repo<<EOF
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
[root@k8s-101 ~]# yum install -y kubelet-1.22.3 kubeadm-1.22.3 kubectl-1.22.3修改 Kubelet 配置文件,设置 cgroup 驱动为 systemd,镜像 pause 使用阿里云的源,然后启动 Kubelet:
[root@k8s-101 ~]# tee /etc/sysconfig/kubelet<<EOF
KUBELET_EXTRA_ARGS="--cgroup-driver=systemd --runtime-cgroups=/systemd/system.slice --kubelet-cgroups=/systemd/system.slice --pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com/google_containers/pause-amd64:3.2"
EOF
[root@k8s-101 ~]# systemctl daemon-reload
[root@k8s-101 ~]# systemctl enable --now kubelet主节点配置
主节点上部署 HAProxy 和 keepalived 来保证主节点高可用。
部署 HAProxy
HAProxy 提供高可用性、负载均衡、基于 TCP 和 HTTP 的代理,支持数以万记的并发连接。此处 HAProxy 为 apiserver 提供反向代理,HAProxy 将所有请求轮询转发到每个 master 节点上。
在所有主节点上安装 HAProxy:
[root@k8s-101 ~]# yum install -y haproxyHAProxy 的配置文件内容相同,前台监听 16443 端口,转发请求到后台 6443 端口上。主要是设置 backend kubernetes-apiserver 中 server 的地址列表,负载均衡模式 balance 默认为轮询的负载算法 roundrobin:
[root@k8s-101 ~]# tee /etc/haproxy/haproxy.cfg<<EOF
#---------------------------------------------------------------------
# Global settings
#---------------------------------------------------------------------
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
#---------------------------------------------------------------------
# kubernetes apiserver frontend which proxys to the backends
#---------------------------------------------------------------------
frontend kubernetes-apiserver
mode tcp
bind *:16443
option tcplog
default_backend kubernetes-apiserver
#---------------------------------------------------------------------
# round robin balancing between the various backends
#---------------------------------------------------------------------
backend kubernetes-apiserver
mode tcp
balance roundrobin
server k8s-101 192.168.1.101:6443 check
server k8s-102 192.168.1.102:6443 check
server k8s-103 192.168.1.103:6443 check
#---------------------------------------------------------------------
# collection haproxy statistics message
#---------------------------------------------------------------------
listen stats
bind *:10001
stats auth admin:4we50meP455w0rd
stats refresh 5s
stats realm HAProxy\ Statistics
stats uri /
EOF启动后服务后,在浏览器访问任意一台主节点 10001 端口来查询状态。登录使用配置文件中的账号 admin 密码 4we50meP455w0rd:
[root@k8s-101 ~]# systemctl enable --now haproxy.service
[root@k8s-101 ~]# systemctl status haproxy
[root@k8s-101 ~]# netstat -ntulp |grep "16443\|10001"
tcp 0 0 0.0.0.0:10001 0.0.0.0:* LISTEN 28052/haproxy
tcp 0 0 0.0.0.0:16443 0.0.0.0:* LISTEN 28052/haproxy 部署 Keepalived
Keepalived 以 VRRP(虚拟路由冗余协议)协议为基础,包括一个 master 和多个 backup。master 劫持 VIP 对外提供服务。master 发送组播,backup 节点收不到 VRRP 包时认为 master 宕机,此时选出剩余优先级最高的节点作为新 master 劫持 VIP。
此处的 Keepalived 的主要作用是为 haproxy 提供 VIP(192.168.1.253)。在 3 个 HAProxy 实例之间提供主备,降低当其中一个 HAProxy 失效时对服务的影响。
先在所有主节点上安装 Keepalived:
[root@k8s-101 ~]# yum -y install keepalived psmisc选主节点 k8s-101 作为 Keepalived 的 MASTER ,配置文件内容如下:
[root@k8s-101 ~]# vi /etc/keepalived/keepalived.conf
global_defs {
router_id LVS_DEVEL
script_user root
enable_script_security
}
vrrp_script check_haproxy {
script "/bin/bash -c 'if [[ $(netstat -nlp | grep 16443) ]]; then exit 0; else exit 1; fi'"
interval 2
weight -11
}
vrrp_instance VI_1 {
state MASTER
interface ens32
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 2G4phJHIK27jPXq2HJs4BG
}
virtual_ipaddress {
192.168.1.253
}
track_script {
check_haproxy
}
}其他节点的配置修改 vrrp_instance VI_1 中角色 state 为 BACKUP,优先级 priority 为 90:
[root@k8s-102 ~]# vi /etc/keepalived/keepalived.conf
global_defs {
router_id LVS_DEVEL
script_user root
enable_script_security
}
vrrp_script check_haproxy {
script "/bin/bash -c 'if [[ $(netstat -nlp | grep 16443) ]]; then exit 0; else exit 1; fi'"
interval 2
weight -11
}
vrrp_instance VI_1 {
state BACKUP
interface ens32
virtual_router_id 51
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 2G4phJHIK27jPXq2HJs4BG
}
virtual_ipaddress {
192.168.1.253
}
track_script {
check_haproxy
}
}配置文件中主要配置项有:
vrrp_script check_haproxy{}:检测 HAProxy 进程是否存活脚本。每 2 秒检测本地 HAProxy 监听端口 16443。如果端口没响应,优先级分数会被减去 11,VIP 地址会转移到更高优先级的节点。state MASTER:指定节点角色。interface ens32:指定 VIP 地址绑定网卡名称。virtual_router_id 51:虚拟路由组的 ID。priority 100:节点优先级。authentication:节点之间认证密码。virtual_ipaddress{}:VIP 虚拟 IP 地址。
配置好后,在所有主节点启动服务:
[root@k8s-101 ~]# systemctl enable --now keepalived.service注意,重启网络服务后,必须连带重启 Keepalived 服务,否则 VIP 地址会失效。
测试故障转移
使用 ip a s 查看当前 VIP 绑定的主机,并在停止绑定主机上停止 Keepalived 或 HAProxy 服务后,观察 VIP 的漂移:
[root@k8s-101 ~]# ip a s
2: ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:f3:57:42 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.101/24 brd 192.168.1.255 scope global noprefixroute ens32
valid_lft forever preferred_lft forever
inet 192.168.1.253/32 scope global ens32
valid_lft forever preferred_lft forever
inet6 fe80::e99f:f473:5c6b:60e9/64 scope link noprefixroute
valid_lft forever preferred_lft forever
[root@k8s-101 ~]# systemctl stop haproxy
[root@k8s-101 ~]# netstat -ntulp |grep 16443
[root@k8s-101 ~]# ip a s
2: ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:f3:57:42 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.101/24 brd 192.168.1.255 scope global noprefixroute ens32
valid_lft forever preferred_lft forever
inet6 fe80::e99f:f473:5c6b:60e9/64 scope link noprefixroute
valid_lft forever preferred_lft forever在 k8s-101 上关闭 HAProxy 服务后,VIP 地址已经转移到别的节点上面。即使 k8s-101 节点重新启动也不会转移回去:
[root@k8s-103 ~]# ip a s
2: ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:50:56:22:32:88 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.103/24 brd 192.168.1.255 scope global noprefixroute ens32
valid_lft forever preferred_lft forever
inet 192.168.1.253/32 scope global ens32
valid_lft forever preferred_lft forever
inet6 fe80::2526:9131:23cc:8de8/64 scope link noprefixroute
valid_lft forever preferred_lft forever建立集群
为了组成高可用集群,至少需要 3 个主节点,否则会出现脑裂现象。
初始化主节点
采用 kubeadm 来部署集群,首先需要初始化一个主节点。
可以生成默认的 kubeadm-master.config 配置文件,并在修改后指定使用该配置运行命令:
[root@k8s-101 ~]# kubeadm config print init-defaults > /etc/kubernetes/kubeadm-master.config
[root@k8s-101 ~]# kubeadm init --config=/etc/kubernetes/kubeadm-master.config --upload-certs或者,可以使用指定的参数来初始化主节点:
[root@k8s-101 ~]# kubeadm init --apiserver-advertise-address=192.168.1.101 --image-repository=registry.aliyuncs.com/google_containers --kubernetes-version=v1.22.3 --service-cidr=10.96.0.0/12 --pod-network-cidr=10.244.0.0/16常见参数配置说明如下:
--apiserver-advertise-address:第一个主节点的 IP 地址,一般为内网地址。--image-repository:设置镜像仓库地址。--kubernetes-version:设置 Kubernetes 版本。版本高于 1.23 无法使用 Docker 容器运行时。--service-cidr:设置服务器通信使用的 IP 网段。默认为10.96.0.0/12--pod-network-cidr:设置内部的 Pod 节点之间网络可以使用的 IP 段。对于使用不同的网络插件,默认值有所不同。常见的网络插件默认值配置如下:- Calico 网络插件:默认为
192.168.0.0/16。 - Flannel 网络插件:默认为
10.244.0.0/16。 - Weave 网络插件:默认为
10.32.0.0/12。
- Calico 网络插件:默认为
--upload-certs:上传证书到kubeadm-certsSecret。--control-plane-endpoint:设置控制节点主机地址。
下面使用声明的变量来生成配置:
[root@k8s-101 ~]# export APISERVER_ADVERTISE_ADDRESS=192.168.1.101
[root@k8s-101 ~]# export KUBERNETES_VERSION=v1.22.3
[root@k8s-101 ~]# export SERVICE_CIDR=10.96.0.0/16
[root@k8s-101 ~]# export POD_NETWORK_CIDR=10.244.0.1/16
[root@k8s-101 ~]# export CONTROL_PLANE_ENDPOINT=192.168.1.253:16443
[root@k8s-101 ~]# mkdir -p /hxz393/local/k8s/config/
[root@k8s-101 ~]# cat <<EOF > /hxz393/local/k8s/config/kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
kubernetesVersion: "${KUBERNETES_VERSION}"
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers
controlPlaneEndpoint: "${CONTROL_PLANE_ENDPOINT}"
networking:
serviceSubnet: "${SERVICE_CIDR}"
podSubnet: "${POD_NETWORK_CIDR}"
dnsDomain: "cluster.local"
EOF
[root@k8s-101 ~]# kubeadm init --config=/hxz393/local/k8s/config/kubeadm-config.yaml --upload-certs
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join k8s-250:6443 --token 66e1on.yh84w71x6mauu6em \
--discovery-token-ca-cert-hash sha256:5849bdad8508feeb3b40e634f7c97f074eb79705d365d097ee75a44374545715 \
--control-plane --certificate-key 337bb228b52a88c297d72102652834aeef9666b847247b2b17471a78236af909
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join k8s-250:6443 --token 66e1on.yh84w71x6mauu6em \
--discovery-token-ca-cert-hash sha256:5849bdad8508feeb3b40e634f7c97f074eb79705d365d097ee75a44374545715 上面是主节点搭建成功后,输出后续操作提示。如果因为拉取镜像时间太长导致失败,可以用下面命令提前拉取镜像:
[root@k8s-101 ~]# kubeadm config images pull --image-repository=registry.aliyuncs.com/google_containers配置 Kubectl
按照提示,将变量声明写入到 .bashrc 中:
[root@k8s-101 ~]# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >>~/.bashrc或者,将 admin.conf 放入 $HOME/.kube 目录中,才能使用 kubectl 命令操作集群:
[root@k8s-101 ~]# mkdir -p $HOME/.kube && cp -i /etc/kubernetes/admin.conf $HOME/.kube/config && cp -i /etc/kubernetes/admin.conf /hxz393/local/k8s/config/admin.conf同样地,可以将 admin.conf 放入其他用户的家目录或其他主机上,以赋予其集群管理权限。请注意修改配置文件的所有者和权限:
[root@k8s-250 ~]$ scp /etc/kubernetes/admin.conf shareuser@192.168.1.248:/home/shareuser/.kube/config
[root@k8s-248 ~]$ chown -R shareuser:shareuser /home/shareuser/.kube
[root@k8s-248 ~]$ chmod -R 755 /home/shareuser/.kube配置 kubectl 命令的自动补全:
[root@k8s-101 ~]# echo "source <(kubectl completion bash)" >>~/.bashrc
[root@k8s-101 ~]# source ~/.bashrc部署网络
可以选择安装高性能的 Underlay 网络,如 Flannel 或 Calico。只能安装其中一种网络。
-
Flannel
官方网站提供的安装 Flannel 网络:
[root@k8s-101 ~]# kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml Warning: policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+ podsecuritypolicy.policy/psp.flannel.unprivileged created clusterrole.rbac.authorization.k8s.io/flannel created clusterrolebinding.rbac.authorization.k8s.io/flannel created serviceaccount/flannel created configmap/kube-flannel-cfg created daemonset.apps/kube-flannel-ds created由于
githubusercontent.com经常连接不通,可以手动将kube-flannel.yml下载下来后部署:[root@k8s-101 ~]# kubectl apply -f /hxz393/local/k8s/apply/kube-flannel.yml -
Calico
使用以下方式安装 Calico 网络:
[root@k8s-101 ~]# wget https://kuboard.cn/install-script/calico/calico-3.9.2.yaml [root@k8s-101 ~]# sed -i "s#192\.168\.0\.0/16#${pod_SUBNET}#" calico-3.9.2.yaml [root@k8s-101 ~]# kubectl apply -f calico-3.9.2.yaml根据官方网站提供的安装方式:
[root@k8s-101 ~]# kubectl create -f https://docs.projectcalico.org/manifests/tigera-operator.yaml [root@k8s-101 ~]# kubectl create -f https://docs.projectcalico.org/manifests/custom-resources.yaml installation.operator.tigera.io/default created
完成部署
等待网络部署完成,所有 8 个容器都部署完毕后,主节点就搭建好了:
[root@k8s-101 ~]# kubectl get pod -n kube-system -o wide --watch
[root@k8s-101 ~]# journalctl -u kubelet -f添加 Node 标签,其中 NodeRole 角色名可以是 master(主节点)或 worker(从节点)。NodeName 是主机名,NodeEnv 可以是 base(基础服务)或 app(应用):
[root@k8s-101 ~]# kubectl label node k8s-101 NodeRole=master
[root@k8s-101 ~]# kubectl label node k8s-101 NodeName=k8s-101
[root@k8s-101 ~]# kubectl label node k8s-101 NodeEnv=local加入集群
加入集群按照以下步骤进行操作。加入失败时,可以在加入命令加上 --v=5 来显示详细错误日志。
获取参数
加入集群所需的 3 个参数如下:
-
Token
token 的有效期为 1 天。在失效后,可以使用
kubeadm token create命令重新创建:[root@k8s-101 ~]# kubeadm token create xjp771.yrjc4oe1thjjt112 [root@k8s-101 ~]# kubeadm token list TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS xjp771.yrjc4oe1thjjt112 23h 2022-04-21T02:14:35Z authentication,signing <none> system:bootstrappers:kubeadm:default-node-token -
Discovery Token CA Cert Hash
获得 discovery-token-ca-cert-hash 参数的方法如下:
[root@k8s-101 ~]# openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //' 1499ca908be1d430887b67d4dbfff06a5374cf3d340d3c0ba9db1aa51ad9ddfb -
Certificate Key
直接更新证书来获取 certificate-key 参数:
[root@k8s-101 ~]# kubeadm init phase upload-certs --upload-certs I0420 10:15:58.086168 6701 version.go:255] remote version is much newer: v1.23.5; falling back to: stable-1.22 [upload-certs] Storing the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace [upload-certs] Using certificate key: 937bf7194bd6e346e177f3a64de9ec01e9043828cb263f0ed80bddc359a351e2
加入从节点
加入从节点只需要使用 token 和 discovery-token-ca-cert-hash 参数。指定集群的 Control Plane 地址(192.168.1.253:16443)或单个主节点的 IP 地址加端口号 6443(192.168.1.101:6443),并使用 kubeadm join 命令将从节点加入集群:
[root@k8s-101 ~]# echo "192.168.1.101 k8s-101" >> /etc/hosts
[root@k8s-101 ~]# kubeadm join k8s-101:6443 --token xjp771.yrjc4oe1thjjt112 --discovery-token-ca-cert-hash sha256:1499ca908be1d430887b67d4dbfff06a5374cf3d340d3c0ba9db1aa51ad9ddfb
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.加入成功后,在主节点给新节点标签:
[root@k8s-101 ~]# kubectl label node k8s-104 NodeRole=worker
[root@k8s-101 ~]# kubectl label node k8s-104 NodeName=k8s-104
[root@k8s-101 ~]# kubectl label node k8s-104 NodeEnv=local
[root@k8s-101 ~]# kubectl label node k8s-104 node-role.kubernetes.io/worker=app加入主节点
加入主节点的步骤与加入从节点类似,多需要提供一个 --certificate-key 参数:
[root@k8s-101 ~]# echo "192.168.1.101 k8s-101" >> /etc/hosts
[root@k8s-101 ~]# kubeadm join k8s-101:644 --token 4sz9hf.dwt05n1ohpb772au \
--discovery-token-ca-cert-hash sha256:864ee6f29ac83d7ec0db3e75c2b54a70ac7622c8c82e52cc71511255febf5b28 \
--control-plane --certificate-key af928d1032d723ae3f16c7218b07afb41b4d588d746bbeb6ed9c657a460591cd添加集群控制权限:
[root@k8s-101 ~]# mkdir -p $HOME/.kube && cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@k8s-101 ~]# echo "source <(kubectl completion bash)" >>~/.bashrc
[root@k8s-101 ~]# source ~/.bashrc添加节点标签:
[root@k8s-101 ~]# kubectl label node k8s-249 NodeRole=master
[root@k8s-101 ~]# kubectl label node k8s-249 NodeName=k8s-249
[root@k8s-101 ~]# kubectl label node k8s-249 NodeEnv=base等待完成
查看已加入的节点:
[root@k8s-101 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-101 Ready control-plane,master 25m v1.22.3
k8s-104 NotReady <none> 95s v1.22.3
k8s-105 NotReady <none> 95s v1.22.3
k8s-106 NotReady <none> 87s v1.22.3使用 --all-namespaces 参数来查看所有节点上的容器运行信息,确保所有的 Pod 都处于运行状态:
[root@k8s-101 ~]# kubectl get pod --all-namespaces -o wide
NAMESPACE NAME READY STATUS AGE IP NODE
kube-system coredns-7d89d9b6b8-6p4wt 1/1 Running 26m 10.244.0.2 k8s-101
kube-system coredns-7d89d9b6b8-dd5h6 1/1 Running 26m 10.244.0.3 k8s-101
kube-system etcd-k8s-101 1/1 Running 26m 192.168.1.101 k8s-101
kube-system kube-apiserver-k8s-101 1/1 Running 26m 192.168.1.101 k8s-101
kube-system kube-controller-manager-k8s-101 1/1 Running 26m 192.168.1.101 k8s-101
kube-system kube-flannel-ds-bhck2 1/1 Running 2m17s 192.168.1.105 k8s-105
[root@k8s-101 ~]# kubectl get all --all-namespaces 移除节点
如果想从集群中移除节点,首先使用 drain 命令驱逐节点上运行的 Pod:
[root@k8s-250 ~]$ kubectl drain k8s-249 --ignore-daemonsets
node/k8s-249 cordoned
WARNING: ignoring DaemonSet-managed Pods: kube-system/kube-flannel-ds-8rfqm, kube-system/kube-proxy-qnxcw
evicting pod base/zookeeper-2
evicting pod base/zookeeper-0在所有的 Pod 转移完成后,可以运行以下命令删除节点(主节点还需要手动修改 etcd 数据库):
[root@k8s-250 ~]$ kubectl delete node k8s-249
node "k8s-249" deleted最后在要移除的节点上运行以下命令:
[root@k8s-249 ~]$ yes | kubeadm reset
[root@k8s-249 ~]$ rm -rf /var/lib/cni/ /etc/cni/net.d $HOME/.kube/config /var/lib/etcd
[root@k8s-249 ~]$ ifconfig cni0 down
[root@k8s-249 ~]$ ip link delete cni0
[root@k8s-249 ~]$ ifconfig flannel.1 down
[root@k8s-249 ~]$ ip link delete flannel.1节点配置
安装完毕后还需要做一些配置修改和初始化工作。
主节点配置
开发环境下,为了允许在主节点上部署应用程序,需要移除主节点上的污点(去除 taint 命令最后的减号 - 则是重新加入污点):
[root@k8s-101 ~]# kubectl taint nodes --all node-role.kubernetes.io/master=true:NoSchedule-
node/k8s-101 untainted
node/k8s-102 untainted
node/k8s-103 untainted
[root@k8s-101 ~]# kubectl get no -o yaml | grep taint -A 5修改 NodePort 端口范围为无限制。在 /etc/kubernetes/manifests/kube-apiserver.yaml 文件中加入一行配置 - --service-node-port-range=1-65535 ,配置会自动更新:
[root@k8s-101 ~]# sed -i '40a\ - --service-node-port-range=1-65535' /etc/kubernetes/manifests/kube-apiserver.yaml
[root@k8s-101 ~]# cat /etc/kubernetes/manifests/kube-apiserver.yaml
- --tls-cert-file=/etc/kubernetes/pki/apiserver.crt
- --tls-private-key-file=/etc/kubernetes/pki/apiserver.key
- --service-node-port-range=1-65535
image: registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.22.3
imagePullPolicy: IfNotPresent注释掉 /etc/kubernetes/manifests/kube-controller-manager.yaml 和 /etc/kubernetes/manifests/kube-scheduler.yaml 文件中的端口绑定,免得健康检查一直报错:
[root@k8s-101 ~]# sed -i "s/ - --port=0/# - --port=0/g" /etc/kubernetes/manifests/kube-controller-manager.yaml
[root@k8s-101 ~]# sed -i "s/ - --port=0/# - --port=0/g" /etc/kubernetes/manifests/kube-scheduler.yaml
[root@k8s-101 ~]# sed -i "s/ - --bind-address=127.0.0.1/ - --bind-address=0.0.0.0/g" /etc/kubernetes/manifests/kube-controller-manager.yaml
[root@k8s-101 ~]# sed -i "s/ - --bind-address=127.0.0.1/ - --bind-address=0.0.0.0/g" /etc/kubernetes/manifests/kube-scheduler.yaml
[root@k8s-101 ~]# systemctl restart kubelet.service
[root@k8s-101 ~]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true","reason":""} 修改节点预留服务器资源,预留 1 核 CPU 加 1 GB 内存:
[root@k8s-101 ~]# sed -i '38a\systemReserved:\n cpu: "500m"\n memory: "500Mi"\nkubeReserved:\n cpu: "500m"\n memory: "500Mi"' /var/lib/kubelet/config.yaml
[root@k8s-101 ~]# systemctl restart kubelet.service从节点配置
修改节点预留服务器资源:
[root@k8s-104 ~]# sed -i '38a\systemReserved:\n cpu: "500m"\n memory: "500Mi"\nkubeReserved:\n cpu: "500m"\n memory: "500Mi"' /var/lib/kubelet/config.yaml
[root@k8s-104 ~]# systemctl restart kubelet.service集群配置
以下是一些常见的配置项目。
建立命名空间
可依据需要建立多命名空间,来区分不同的环境。例如:用 dev 表示开发环境、用 test 表示测试环境、用 base 表示基础服务环境:
[root@k8s-101 ~]# tee /hxz393/local/k8s/apply/kube-namespaces.yml<<EOF
apiVersion: v1
kind: Namespace
metadata:
name: local
EOF
[root@k8s-101 ~]# kubectl apply -f /hxz393/local/k8s/apply/kube-namespaces.yml
[root@k8s-101 ~]# kubectl get namespaces
NAME STATUS AGE
default Active 69m
kube-node-lease Active 69m
kube-public Active 69m
kube-system Active 69m
local Active 23m绑定权限
有时为了测试目的,需要将集群管理员角色绑定到对应命名空间默认 sa(service account)账号上。这样默认命名空间中应用可以访问其他命名空间的资源:
[root@k8s-101 ~]# tee /nanruan/test/k8s/apply/kube-crb.yml<<EOF
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: test-crb
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: default
namespace: local
EOF
[root@k8s-101 ~]# kubectl apply -f /nanruan/test/k8s/apply/test-crb.yml阿里云部署
在阿里云上部署 Kubernetes 时,ECS 不支持自建 VIP。但将 SLB 的 VIP 指定为高可用地址时,初始化主节点会失败。这是因为 4 层 SLB 不支持其调度的后端服务器访问其 VIP,也就是服务器不能同时充当服务端和客户端。
解决方法如下:
- 在从节点部署
HAProxy,并监听16443端口,后端服务器指向主节点6443端口。 - 在 CLB(传统型负载均衡,原 SLB)上新建虚拟服务器组
k8s-haproxy,将安装有HAProxy的从节点加进去,监听端口为16443。 - 在监听页新建监听配置
k8s_haproxy,选择监听TCP/6443端口,后端服务器选择虚拟服务器组k8s-haproxy,开启健康检查,提交。 - 如果不需要通过外网来管理集群,可以修改监听
k8s_haproxy的访问控制。例如添加内网 IP 地址段172.16.0.0/16到白名单,这样可以防止集群对外暴露。 - 在建立集群时,配置
controlPlaneEndpoint的值为<CLB内网IP地址>:6443。例如:--control-plane-endpoint=172.16.17.100:6443。 - 加入集群时,使用
controlPlaneEndpoint的值。例如:kubeadm join 172.16.17.100:6443。
如果需要通过外网来管理集群,可在主节点上将 CLB 的外网 IP 地址更新进去,重新生成证书:
[root@k8s-master1-pro ~]# mkdir -pv /opt/cert && mv /etc/kubernetes/pki/apiserver.* /opt/cert
[root@k8s-master1-pro ~]# kubeadm init phase certs apiserver --apiserver-advertise-address 172.16.17.100 --apiserver-cert-extra-sans 110.112.110.102 --apiserver-cert-extra-sans 172.16.17.99 --apiserver-cert-extra-sans 80.114.163.80其他关于解决此问题的参考连接:
https://www.cnblogs.com/gmmy/p/12372805.html
https://www.cnblogs.com/noah-luo/p/13218837.html
https://zhuanlan.zhihu.com/p/107703112
https://blog.51cto.com/caiyuanji/2405434
https://www.jianshu.com/p/ba94db1c3599
https://blog.csdn.net/weixin_44334279/article/details/119355653
https://www.jianshu.com/p/d645bbe8e621
https://www.kubernetes.org.cn/7033.html
单点集群部署
这里以一主一从的方式,搭建单主节点集群。主节点系统为 Ubuntu。
安装组件
在所有节点安装基础组件 Kubectl、Kubelet 和 Kubeadm,版本选择为 1.23.17:
root@ubuntu22:~# curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo apt-key add -
root@ubuntu22:~# apt-add-repository -y "deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main"
root@ubuntu22:~# apt install -y kubelet=1.23.17-00 kubeadm=1.23.17-00 kubectl=1.23.17-00
root@ubuntu22:~# tee /etc/sysconfig/kubelet<<EOF
KUBELET_EXTRA_ARGS="--cgroup-driver=systemd --runtime-cgroups=/systemd/system.slice --kubelet-cgroups=/systemd/system.slice --pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com/google_containers/pause-amd64:3.2"
EOF
root@ubuntu22:~# systemctl daemon-reload
root@ubuntu22:~# systemctl enable --now kubelet建立集群
首先初始化一个主节点。
声明变量
设置的控制中心地址本机 IP 地址:
root@ubuntu22:~# export APISERVER_ADVERTISE_ADDRESS=192.168.0.102
root@ubuntu22:~# export KUBERNETES_VERSION=v1.23.17
root@ubuntu22:~# export SERVICE_CIDR=10.96.0.0/12
root@ubuntu22:~# export POD_NETWORK_CIDR=10.244.0.0/16
root@ubuntu22:~# export CONTROL_PLANE_ENDPOINT=192.168.0.102:6443初始化
使用 kubeadm init 命令执行初始化:
root@ubuntu22:~# mkdir -p /hxz393/local/k8s/{apply,config}
root@ubuntu22:~# cat <<EOF > /hxz393/local/k8s/config/kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
kubernetesVersion: "${KUBERNETES_VERSION}"
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers
controlPlaneEndpoint: "${CONTROL_PLANE_ENDPOINT}"
networking:
serviceSubnet: "${SERVICE_CIDR}"
podSubnet: "${POD_NETWORK_CIDR}"
dnsDomain: "cluster.local"
EOF
root@ubuntu22:~# kubeadm init --config=/hxz393/local/k8s/config/kubeadm-config.yaml --upload-certs成功后输出后续操作提示,可以记一下加入集群命令。
获取权限
获取 root 用户集群管理权:
root@ubuntu22:~# mkdir -p $HOME/.kube && cp -i /etc/kubernetes/admin.conf $HOME/.kube/config && cp -i /etc/kubernetes/admin.conf /hxz393/local/k8s/config/admin.conf
root@ubuntu22:~# echo "source <(kubectl completion bash)" >>~/.bashrc
root@ubuntu22:~# source ~/.bashrc部署网络
部署 flannel 网络插件:
root@ubuntu22:~# kubectl apply -f /hxz393/local/k8s/apply/kube-flannel.yml完成部署
给主节点添加标签:
root@ubuntu22:~# kubectl label node ubuntu22 NodeRole=master
root@ubuntu22:~# kubectl label node ubuntu22 NodeName=ubuntu22
root@ubuntu22:~# kubectl label node ubuntu22 NodeEnv=pre加入集群
加入从节点只需要运行集群建立后的提示命令:
[root@centos7 ~]# echo "192.168.0.102 ubuntu22" >> /etc/hosts
[root@centos7 ~]# kubeadm join 192.168.0.102:6443 --token 8owkqz.jopga29w7j9f8q6k \
--discovery-token-ca-cert-hash sha256:1f796318f606fafa7aa1e8429707c752533b5d534da0108f30b5a423bd386215 添加从节点标签:
root@ubuntu22:~# kubectl label node centos7 NodeName=centos7
root@ubuntu22:~# kubectl label node centos7 NodeEnv=pre
root@ubuntu22:~# kubectl label node centos7 node-role.kubernetes.io/worker=app主节点配置
视需要移除主节点上的污点来允许部署:
root@ubuntu22:~# kubectl taint nodes --all node-role.kubernetes.io/master=true:NoSchedule-修改静态配置:
root@ubuntu22:~# sed -i '40a\ - --service-node-port-range=1-65535' /etc/kubernetes/manifests/kube-apiserver.yaml
root@ubuntu22:~# sed -i '40a\ - --service-node-port-range=1-65535' /etc/kubernetes/manifests/kube-apiserver.yaml
root@ubuntu22:~# sed -i "s/ - --port=0/# - --port=0/g" /etc/kubernetes/manifests/kube-controller-manager.yaml
root@ubuntu22:~# sed -i "s/ - --port=0/# - --port=0/g" /etc/kubernetes/manifests/kube-scheduler.yaml
root@ubuntu22:~# sed -i "s/ - --bind-address=127.0.0.1/ - --bind-address=0.0.0.0/g" /etc/kubernetes/manifests/kube-controller-manager.yaml
root@ubuntu22:~# sed -i "s/ - --bind-address=127.0.0.1/ - --bind-address=0.0.0.0/g" /etc/kubernetes/manifests/kube-scheduler.yaml
root@ubuntu22:~# sed -i '38a\systemReserved:\n cpu: "500m"\n memory: "500Mi"\nkubeReserved:\n cpu: "500m"\n memory: "500Mi"' /var/lib/kubelet/config.yaml
root@ubuntu22:~# systemctl restart kubelet.service建立命名空间
建立命名空间 local 表示本地发布环境:
root@ubuntu22:~# tee /hxz393/local/k8s/apply/kube-namespaces.yml<<EOF
apiVersion: v1
kind: Namespace
metadata:
name: pre
EOF
root@ubuntu22:~# kubectl apply -f /hxz393/local/k8s/apply/kube-namespaces.yml集群升级
整个集群升级需要分三步进行:
- 第一步是主节点升级
kubeadm和kubectl。 - 第二步是主节点升级
kubelet。 - 第三步是从节点升级
kubelet。
主节点升级 kubeadm 和 kubectl 不会对集群的运行产生影响:
[root@k8s-250 ~]$ yum list | grep 'kubeadm\|kubectl\|kubelet'
kubeadm.x86_64 1.22.3-0 @kubernetes
kubectl.x86_64 1.22.3-0 @kubernetes
kubelet.x86_64 1.22.3-0 @kubernetes
kubeadm.x86_64 1.23.5-0 kubernetes
kubectl.x86_64 1.23.5-0 kubernetes
kubelet.x86_64 1.23.5-0 kubernetes
[root@k8s-250 ~]$ yum -y install kubeadm-1.23.5-0 kubectl-1.23.5-0
[root@k8s-250 ~]$ kubeadm upgrade plan
[root@k8s-250 ~]$ kubeadm upgrade apply v1.23.5-0 --config /nanruan/base/k8s/kubeadm/kubeadm-config.yaml主节点和从节点升级 kubelet 的步骤是一样的。首先禁用调度,然后升级并重启 kubelet,最后恢复允许调度:
[root@k8s-250 ~]$ kubectl drain k8s-250 --ignore-daemonsets
[root@k8s-250 ~]$ yum -y install kubelet-1.23.5-0
[root@k8s-250 ~]$ systemctl daemon-reload
[root@k8s-250 ~]$ systemctl restart kubelet
[root@k8s-250 ~]$ systemctl status kubelet
[root@k8s-250 ~]$ kubectl uncordon k8s-250
[root@k8s-250 ~]$ kubectl get nodes
[root@k8s-250 ~]$ kubectl get all --all-namespaces故障处理
一些集群组建时遇到的问题。
没有 pod-network-cidr
在安装 Flannel 时,出现错误提示缺少分配的 Pod CIDR。这可能是因为在使用 kubeadm 初始化时没有指定 --pod-network-cidr 参数,或者 kube-flannel.yml 文件中的 “Network” 字段与 --pod-network-cidr 参数不一致:
[root@server4-master ~]$ kubectl logs -n kube-system kube-flannel-ds-7xp24
I1103 04:42:22.796211 1 vxlan.go:137] VXLAN config: VNI=1 Port=0 GBP=false Learning=false DirectRouting=false
E1103 04:42:22.797028 1 main.go:325] Error registering network: failed to acquire lease: node "server4-master" pod cidr not assigned
I1103 04:42:22.797248 1 main.go:439] Stopping shutdownHandler...要解决此问题,可以修改 kube-controller-manager.yaml 配置文件,在其中添加 - --allocate-node-cidrs=true 和 - --cluster-cidr=10.244.0.0/16 参数:
[root@server4-master ~]$ vi /etc/kubernetes/manifests/kube-controller-manager.yaml
spec:
containers:
- command:
- kube-controller-manager
- --allocate-node-cidrs=true
- --cluster-cidr=10.244.0.0/16然后,删除错误的 Flannel 容器并重新创建,这样就可以使用正确的配置了:
[root@server4-master ~]$ kubectl delete pod -n kube-system kube-flannel-*
[root@server4-master ~]$ kubectl cluster-info dump | grep -m 1 cluster-cidr
"--cluster-cidr=10.244.0.0/16",没有 controlPlaneEndpoint
在将第二个主节点加入已存在的单节点集群过程中,预检阶段会报错缺少 controlPlaneEndpoint。这是因为在初始化时没有指定 --control-plane-endpoint 参数导致的:
[root@server1 ~]$ kubeadm join 192.168.2.204:6443 --token nre8hl.4awo2mnyxr5l0tsu --discovery-token-ca-cert-hash sha256:8055ad40e280bc4b48b0c3b4daea9aa3f515d3b2fea5fb3ae3fcad398c325a52 --control-plane --certificate-key 5ac22cea4cfc19753cd289c96b968957554b4e4204fe47fc3f56a53dded96716
error execution phase preflight:
One or more conditions for hosting a new control plane instance is not satisfied.
unable to add a new control plane instance a cluster that doesn't have a stable controlPlaneEndpoint address
Please ensure that:
* The cluster has a stable controlPlaneEndpoint address.
* The certificates that must be shared among control plane instances are provided.要解决此问题,可以使用 kubectl edit 命令编辑 kubeadm-config 配置文件,并将 controlPlaneEndpoint 地址添加为虚拟 IP 或正在运行的主节点的 IP:
[root@server4-master ~]$ kubectl edit cm kubeadm-config -n kube-system
imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
controlPlaneEndpoint: 192.168.2.204:6443
kubernetesVersion: v1.22.3
networking:
dnsDomain: cluster.local
podSubnet: 10.244.0.0/16保存并退出编辑器。然后,重新执行 kubeadm join 命令将第二个主节点加入集群。这样就能成功添加第二个主节点,完成集群的扩容。
Token 过期
当加入集群时出现错误:
x509: certificate has expired or is not yet valid
可以重新生成令牌:
[root@k8s-master ~]$ kubeadm token create
87668a.lfvdqsr3l5ijlode
[root@k8s-master ~]$ kubeadm token list
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
1yrznt.lzj1kl0qecosl4es 23h 2019-07-21T13:14:33+08:00 authentication,signing <none> system:bootstrappers:kubeadm:default-node-token
87668a.lfvdqsr3l5ijlode 23h 2019-07-21T13:24:28+08:00 authentication,signing <none> system:bootstrappers:kubeadm:default-node-token
[root@server7-master ~]$ kubeadm init phase upload-certs --upload-certs然后在客户端同步时间,并再次尝试加入集群:
[root@k8s-node1 ~]$ ntpdate cn.pool.ntp.org
20 Jul 13:25:59 ntpdate[118642]: step time server 199.182.204.197 offset 137559.272548 sec证书过期
可以使用以下命令查看证书的有效期:
[root@server4-master ~]$ kubeadm certs check-expiration
[check-expiration] Reading configuration from the cluster...
[check-expiration] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED
admin.conf Nov 03, 2022 05:36 UTC 217d no
apiserver Nov 03, 2022 05:36 UTC 217d ca no
apiserver-etcd-client Nov 03, 2022 05:36 UTC 217d etcd-ca no
apiserver-kubelet-client Nov 03, 2022 05:36 UTC 217d ca no
controller-manager.conf Nov 03, 2022 05:36 UTC 217d no
etcd-healthcheck-client Nov 03, 2022 05:36 UTC 217d etcd-ca no
etcd-peer Nov 03, 2022 05:36 UTC 217d etcd-ca no
etcd-server Nov 03, 2022 05:36 UTC 217d etcd-ca no
front-proxy-client Nov 03, 2022 05:36 UTC 217d front-proxy-ca no
scheduler.conf Nov 03, 2022 05:36 UTC 217d no
CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED
ca Nov 01, 2031 05:36 UTC 9y no
etcd-ca Nov 01, 2031 05:36 UTC 9y no
front-proxy-ca Nov 01, 2031 05:36 UTC 9y no 分别在所有主节点上重新生成所有证书:
[root@server4-master ~]$ kubeadm certs renew all
[renew] Reading configuration from the cluster...
[renew] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
certificate embedded in the kubeconfig file for the admin to use and for kubeadm itself renewed
certificate for serving the Kubernetes API renewed
certificate the apiserver uses to access etcd renewed
certificate for the API server to connect to kubelet renewed
certificate embedded in the kubeconfig file for the controller manager to use renewed
certificate for liveness probes to healthcheck etcd renewed
certificate for etcd nodes to communicate with each other renewed
certificate for serving etcd renewed
certificate for the front proxy client renewed
certificate embedded in the kubeconfig file for the scheduler manager to use renewed
Done renewing certificates. You must restart the kube-apiserver, kube-controller-manager, kube-scheduler and etcd, so that they can use the new certificates.根据提示分别在所有主节点上重启组件容器:
[root@server4-master ~]$ docker ps | grep -E 'k8s_kube-apiserver|k8s_kube-controller-manager|k8s_kube-scheduler|k8s_etcd_etcd' | awk -F ' ' '{print $1}' |xargs docker restart更新管理配置文件:
[root@server4-master ~]$ mkdir -p $HOME/.kube && cp -i /etc/kubernetes/admin.conf $HOME/.kube/config && cp -i /etc/kubernetes/admin.conf /hxz393/local/k8s/config/admin.conf证书不符
如果在加入集群时出现错误:
x509: certificate is valid for 10.96.0.1, 192.168.2.204, not 192.168.2.199
提示证书的 IP 地址不符合要求,这通常在更新节点的 apiserver-advertise-address 或 controlPlaneEndpoint 时会发生。解决方法是删除当前集群下 apiserver 的证书和密钥,然后重新生成:
[root@server4 ~]$ rm -f /etc/kubernetes/pki/apiserver.*设置原先主机的 IP 地址为 192.168.2.204,现在的虚拟 IP 地址为 192.168.2.199:
[root@server4 ~]$ kubeadm init phase certs apiserver --apiserver-advertise-address 192.168.2.204 --apiserver-cert-extra-sans 192.168.2.199
[root@server4 ~]$ kubeadm alpha certs renew admin.conf
Kubeadm experimental sub-commands重启 API Server,然后查看证书:
[root@server4 ~]$ kubectl -n kube-system delete pod kube-apiserver-server4 kube-apiserver-server6
pod "kube-apiserver-server4" deleted
pod "kube-apiserver-server6" deleted
[root@server4 ~]$ openssl x509 -in /etc/kubernetes/pki/apiserver.crt -noout -text
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 2687592491658220129 (0x254c3f21b64b9261)
Signature Algorithm: sha256WithRSAEncryption
Issuer: CN=kubernetes
Validity
Not Before: Apr 4 16:21:14 2022 GMT
Not After : Apr 19 13:48:19 2023 GMT将新的 admin.conf 文件复制到其他需要访问集群的主节点上:
[root@server4 ~]$ scp /etc/kubernetes/admin.conf root@192.168.2.206:./.kube现在可以加入新的主节点了。
cni0 地址错误
在重新构建 Kubernetes 集群后,由于节点上残留了未删除的虚拟网卡,导致创建 Pod 失败,提示 cni0 地址冲突:
[root@server7-master ~]$ kubectl describe po kubia-74967b5695-ftk77
Warning FailedCreatePodSandBox 56s (x4 over 59s) kubelet (combined from similar events): Failed to create pod sandbox: rpc error: code = Unknown desc = failed to set up sandbox container "18dd9bc5076666ed605b2d3331864859454878d7e1f9fae2160f1be71c59c48f" network for pod "kubia-74967b5695-ftk77": networkPlugin cni failed to set up pod "kubia-74967b5695-ftk77_default" network: failed to delegate add: failed to set bridge addr: "cni0" already has an IP address different from 10.100.4.1/24
[root@server6 ~]$ ip a
5: cni0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default qlen 1000
link/ether 92:1d:b1:d9:ba:19 brd ff:ff:ff:ff:ff:ff
inet 10.100.9.1/24 brd 10.100.9.255 scope global cni0
valid_lft forever preferred_lft forever解决方法是手动删除网卡,让它重新创建:
[root@server6 ~]$ ifconfig cni0 down
[root@server6 ~]$ ip link delete cni0
[root@server6 ~]$ ip a
926: cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default qlen 1000
link/ether 92:6a:c8:8b:2c:5b brd ff:ff:ff:ff:ff:ff
inet 10.100.4.1/24 brd 10.100.4.255 scope global cni0
valid_lft forever preferred_lft foreveretcd 错误
在 etcd 中存在已被删除的节点记录时,当节点重新加入集群时会报错:
etcd cluster is not healthy: failed to dial endpoint
这时需要手动维护 etcd 数据库。
进入节点的 etcd 容器内部,查询 etcd 集群的成员列表,然后删除错误的成员,这样集群就恢复正常了:
[root@server6 ~]$ kubectl -n kube-system exec -it etcd-k8s-239 -- sh
sh-5.0# export ETCDCTL_API=3
sh-5.0# alias etcdctl='etcdctl --endpoints=https://127.0.0.1:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key'
sh-5.0# etcdctl member list
2e1d3dc8363ee756, started, server5, https://192.168.2.205:2380, https://192.168.2.205:2379, false
4b8b623fba4c1f57, started, server6, https://192.168.2.206:2380, https://192.168.2.206:2379, false
ad703513a2c4e54a, started, server4, https://192.168.2.204:2380, https://192.168.2.204:2379, false
sh-5.0# etcdctl member remove 63bfe05c4646fb08没找到 resolv.conf 文件
如果主节点为 Ubuntu,从节点为 CentOS,从节点加入集群后,kube-flannel 容器报错:
Failed to create pod sandbox: open /run/systemd/resolve/resolv.conf: no such file or directory
这是由于 CentOS 和 Ubuntu 系统 DNS 服务器配置文件 resolv.conf 所在位置不同导致。
可以在 CentOS 上创立一个软链接,将 /etc/resolv.conf 文件链接到 /run/systemd/resolve/resolv.conf:
[root@centos7 ~]# mkdir /run/systemd/resolve/
[root@centos7 ~]# ln -s /etc/resolv.conf /run/systemd/resolve/resolv.conf重启 kubelet 服务以使更改生效:
[root@centos7 ~]# systemctl restart kubelet至此报错解决。
备份恢复
单主节点集群一定要做好备份工作。
查看 etcd 配置
在使用 kubeadm 部署的 Kubernetes 集群中,etcd 作为容器运行,并通过本地挂载来存储数据库和配置文件:
[root@server7-master ~]$ ll /var/lib/etcd/member/snap
total 5124
-rw-r--r-- 1 root root 9851 Apr 1 03:37 0000000000000012-00000000000222f1.snap
-rw-r--r-- 1 root root 9851 Apr 1 04:46 0000000000000012-0000000000024a02.snap
-rw-r--r-- 1 root root 9851 Apr 1 05:55 0000000000000012-0000000000027113.snap
-rw-r--r-- 1 root root 9851 Apr 1 07:04 0000000000000012-0000000000029824.snap
-rw-r--r-- 1 root root 9851 Apr 1 08:14 0000000000000012-000000000002bf35.snap
-rw-------. 1 root root 5185536 Apr 1 08:58 db
[root@server7-master ~]$ ll /etc/kubernetes/pki/etcd
total 32
-rw-r--r--. 1 root root 1086 Mar 31 11:49 ca.crt
-rw-------. 1 root root 1679 Mar 31 11:49 ca.key
-rw-r--r--. 1 root root 1159 Mar 31 11:49 healthcheck-client.crt
-rw-------. 1 root root 1675 Mar 31 11:49 healthcheck-client.key
-rw-r--r--. 1 root root 1212 Mar 31 11:49 peer.crt
-rw-------. 1 root root 1679 Mar 31 11:49 peer.key
-rw-r--r--. 1 root root 1212 Mar 31 11:49 server.crt
-rw-------. 1 root root 1675 Mar 31 11:49 server.key其中,以 “.snap” 结尾的文件是快照文件。
安装 etcd 客户端
在主节点上安装 etcd 客户端:
[root@server7-master ~]$ yum install -y etcd
[root@server7-master ~]$ etcdctl --version
etcdctl version: 3.3.11
API version: 2查看 etcd 数据库
首先尝试连接到本地 etcd 数据库:
[root@server7-master ~]$ export ETCDCTL_API=3
[root@server4-master ~]$ etcdctl version
etcdctl version: 3.3.11
API version: 3.3
[root@server7-master ~]$ export ETCD="etcdctl --endpoints https://127.0.0.1:2379 --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key --cacert=/etc/kubernetes/pki/etcd/ca.crt"
[root@server7-master ~]$ $ETCD member list
273040abda86d599, started, server9-node1, https://192.168.2.209:2380, https://192.168.2.209:2379
4c80ad008d949110, started, server8-node1, https://192.168.2.208:2380, https://192.168.2.208:2379
dcddbc08262b69e1, started, server7-master, https://192.168.2.207:2380, https://192.168.2.207:2379查看所有 Pod 对象的存储名称:
[root@server7-master ~]$ $ETCD get /registry/pods --prefix --keys-only
/registry/pods/default/kubia-74967b5695-bzxtf
/registry/pods/default/kubia-74967b5695-vhjkz使用命令备份恢复
使用 etcdctl snapshot save 命令将 etcd 数据库备份到当前目录:
[root@server7-master ~]$ $ETCD snapshot save snap.db
Snapshot saved at snap.db
[root@server7-master ~]$ $ETCD snapshot status snap.db
c477d6ef, 144130, 1216, 5.2 MB首先对一个正在运行的服务进行缩容:
[root@server7-master ~]$ kubectl get po
NAME READY STATUS RESTARTS AGE
kubia-74967b5695-bzxtf 1/1 Running 2 (7h19m ago) 20h
kubia-74967b5695-vhjkz 1/1 Running 2 (7h19m ago) 20h
kubia-74967b5695-wsd5c 1/1 Running 2 (7h19m ago) 20h
[root@server7-master ~]$ kubectl scale deployment kubia --replicas=1
deployment.apps/kubia scaled然后暂停 API Server 和 etcd 容器:
[root@server7-master ~]$ systemctl stop kubelet
[root@server7-master ~]$ docker stop $(docker ps -q) & docker rm -f $(docker ps -aq)
[root@server7-master ~]$ mv /etc/kubernetes/manifests /etc/kubernetes/manifests.bak
[root@server7-master ~]$ mv /var/lib/etcd/ /var/lib/etcd.bak恢复 etcd 数据库:
[root@server7-master ~]$ $ETCD snapshot restore snap.db --data-dir=/var/lib/etcd
2022-04-01 09:40:54.304594 I | mvcc: restore compact to 143285
2022-04-01 09:40:54.315885 I | etcdserver/membership: added member 8e9e05c52164694d [http://localhost:2380] to cluster cdf818194e3a8c32恢复运行 API Server 和 etcd 容器后,再次验证数据:
[root@server7-master ~]$ mv /etc/kubernetes/manifests.bak /etc/kubernetes/manifests
[root@server7-master ~]$ systemctl start kubelet使用文件备份恢复
由于版本问题,使用 etcdctl 备份恢复的数据库经常出错,因此可以使用备份文件夹的方式来备份数据库:
[root@server4 ~]$ cp -r /var/lib/etcd/ /root/etcd/
[root@server4 ~]$ ll /root/etcd/
total 0
drwx------. 4 root root 29 Apr 5 02:08 member进行一系列操作后:
[root@server4 ~]$ kubectl scale deployment kubia --replicas=11
deployment.apps/kubia scaled
[root@server4 ~]$ kubectl create ns pro
namespace/pro created停止 kubelet,删除所有 Docker 容器,删除原数据库文件,然后将备份文件夹复制回来,启动 kubelet:
[root@server4 ~]$ systemctl stop kubelet
[root@server4 ~]$ docker stop $(docker ps -q) & docker rm -f $(docker ps -aq)
[root@server4 ~]$ rm -rf /var/lib/etcd/
[root@server4 ~]$ cp -r /root/etcd/ /var/lib/etcd/
[root@server4 ~]$ systemctl start kubelet恢复的数据将回到备份时的状态。