K8s 组件介绍
API 服务器
K8s API 服务器作为中心组件,其他组件或客户端都会调用它。API 服务器以 RESTful API 的形式提供了可以查询、修改集群状态的 CRUD (Create, Read, Update, Delete) 接口,并将状态存储到 etcd 中。
API 服务器除了提供一种一致的方式来存储对象,还对这些对象进行校验,以确保其合法性。除了校验之外,API 服务器还会处理乐观锁。
kubectl 是 API 服务的一个客户端之一。
工作流程
当 kubectl 通过一个 HTTP POST 请求将配置文件内容发布到 API 服务器后,API 处理的流程如下:
-
通过认证插件认证客户端
首先,API 服务器需要对发送请求的客户端进行认证。通过依次调用配置在 API 服务器上的一个或多个认证插件,直到确认请求发送者的身份。根据认证方式,可以从客户端证书或 HTTP 标头中获取用户信息。插件提取客户端的用户名、用户 ID 和归属组信息。
-
通过授权插件为客户端授权
API 服务器还可以配置使用一个或多个授权插件,以决定认证用户是否可以对请求的资源执行请求操作。一旦确认用户拥有权限,API 服务器进入下一步操作。
-
通过准入控制插件验证并修改资源请求
如果请求尝试创建、修改或删除资源,则需要经过准入控制插件的验证。这些插件会验证资源请求,并根据不同的原因对资源进行修改。它们可能会将资源定义中未配置的字段初始化为默认值,可能会修改与请求相关的其他资源,同时也可能因为某些原因拒绝请求。
如果请求只是尝试读取数据,则不会进行准入控制的验证。
常用的准入控制插件包括:AlwaysPullImages、ServiceAccount、NamespaceLifecycle、ResourceQuota 等。
-
验证资源并进行持久化存储
请求通过了所有的准入控制插件后,API 服务器会验证存储在 etcd 中的对象,并向客户端返回响应。
资源变更
API 服务器只负责启动控制器,以及其他一些组件来监控已部署资源的变更.控制面板可以请求订阅资源被创建,修改或删除的通知.
客户端通过创建到 API 服务器的 HTTP 连接来监听变更.每当更新对象,服务器把新版本对象发送至所有监听该对象的客户端.
kubectl 工具作为 API 服务器的客户端之一也支持监听资源.例如部署应用时,可以通过在 get 命令后加–watch 参数,每当有变化就会收到通知:
[root@server4-master ~]$ kubectl get po --watch
NAME READY STATUS RESTARTS AGE
kubia-0 1/1 Running 0 19h
kubia-1 1/1 Running 0 19h
kubia-2 1/1 Running 0 19hDownward API
对于无法预先知道的数据,K8s Downward API 允许我们通过环境变量或文件(downwardAPI 卷)将 Pod 的元数据公开给外部(传递给容器内的 Pod)。这种方式主要是将从 Pod 的定义和状态中获取的数据作为环境变量和文件的值传递。
目前可以传递给容器的数据包括:
- Pod 名称
- Pod 的 IP 地址
- Pod 所属的命名空间
- Pod 运行的节点名称
- Pod 运行的服务账户名称
- 每个容器请求的 CPU 和内存使用量
- 每个容器可使用的 CPU 和内存限制
- Pod 的标签
- Pod 的注解
由于可以在 Pod 运行时修改 Pod 的标签和注解,因此无法通过环境变量来公开修改后的新值。
Downward API 在处理已在环境变量中的部分数据的现有应用程序时特别有用,无需修改应用程序或编写脚本来公开元数据。
通过环境变量暴露
创建一个简单的单容器来暴露 Pod 常见的 7 种数据:
[root@server4-master ~]$ vi dow.yaml
apiVersion: v1
kind: Pod
metadata:
name: downward
spec:
containers:
- name: main
image: busybox
command: ["sleep", "9999"]
resources:
requests:
cpu: 15m
memory: 500Ki
limits:
cpu: 100m
memory: 8Mi
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: SERVICE_ACCOUNT
valueFrom:
fieldRef:
fieldPath: spec.serviceAccountName
- name: CONTAINER_CPU_REQUEST_MILLICORES
valueFrom:
resourceFieldRef:
resource: requests.cpu
divisor: 1m
- name: CONTAINER_MEMORY_LIMIT_KIBIBYTES
valueFrom:
resourceFieldRef:
resource: limits.memory
divisor: 1Ki其中,fieldRef 参考的数据来自使用 kubectl get po downward -o yaml 展示的结果,resourceFieldRef 参考的是 spec.containers 中的 resources。如下图所示:
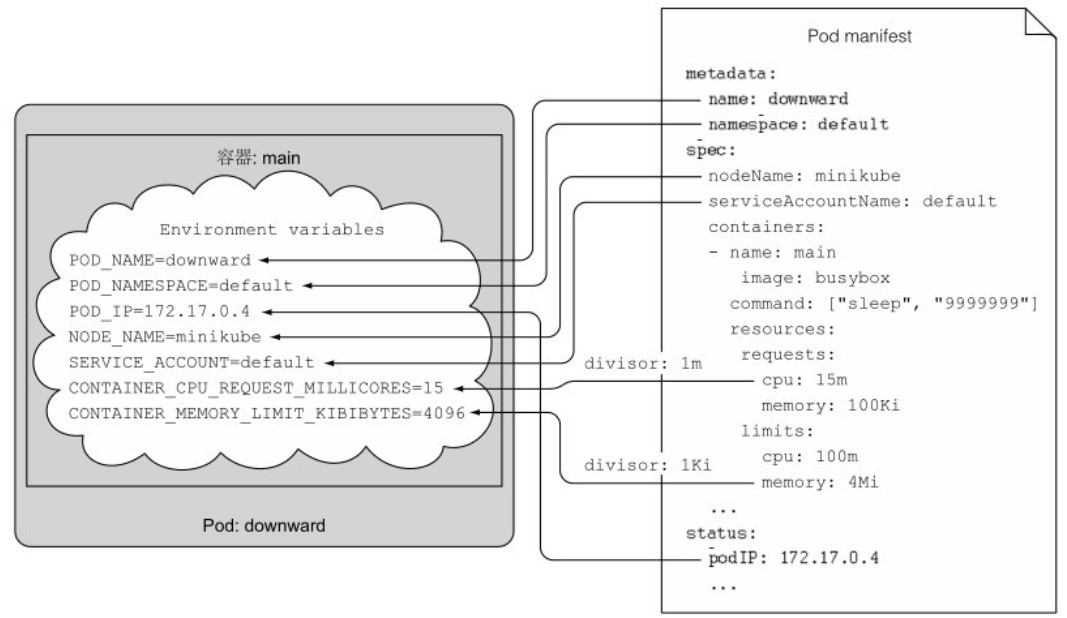
对于暴露的资源请求和限制变量,通过 divisor 设置了一个基数单位,最后暴露的是实际数据除以基数单位得到的值。例如,CPU 请求基数为 1 millicore,环境变量展示的值为 15,内存限制基数为 1 Kibibyte,环境变量展示的值为 8192。
创建完 Pod 后,查询容器中的所有环境变量:
[root@server4-master ~]$ kubectl exec downward -- env
SERVICE_ACCOUNT=default
CONTAINER_CPU_REQUEST_MILLICORES=15
CONTAINER_MEMORY_LIMIT_KIBIBYTES=8192
POD_NAME=downward
POD_NAMESPACE=default
POD_IP=10.244.244.211
NODE_NAME=server6-node2所有在该容器中运行的进程都可以读取并使用所需的变量。
通过 Downward API 卷传递
使用卷来暴露元数据需要显式地指定元数据字段:
[root@server4-master ~]$ vi dow-v.yaml
apiVersion: v1
kind: Pod
metadata:
name: downward
labels:
foo: bar
annotations:
key1: value1
key2: |
multi
line
value
spec:
containers:
- name: main
image: busybox
command: ["sleep", "9999"]
resources:
requests:
cpu: 15m
memory: 500Ki
limits:
cpu: 100m
memory: 8Mi
volumeMounts:
- name: downward
mountPath: /etc/downward
volumes:
- name: downward
downwardAPI:
items:
- path: "podName"
fieldRef:
fieldPath: metadata.name
- path: "podNamespace"
fieldRef:
fieldPath: metadata.namespace
- path: "labels"
fieldRef:
fieldPath: metadata.labels
- path: "annotations"
fieldRef:
fieldPath: metadata.annotations
- path: "containerCpuRequestMilliCores"
resourceFieldRef:
containerName: main
resource: requests.cpu
divisor: 1m
- path: "containerMemoryLimitBytes"
resourceFieldRef:
containerName: main
resource: limits.memory
divisor: 1Downward API 卷被挂载到 /etc/downward/ 目录下,卷类型为 DownwardAPI,卷包含的文件会通过卷定义中的 downwardAPI.items 属性来定义。如下图所示:
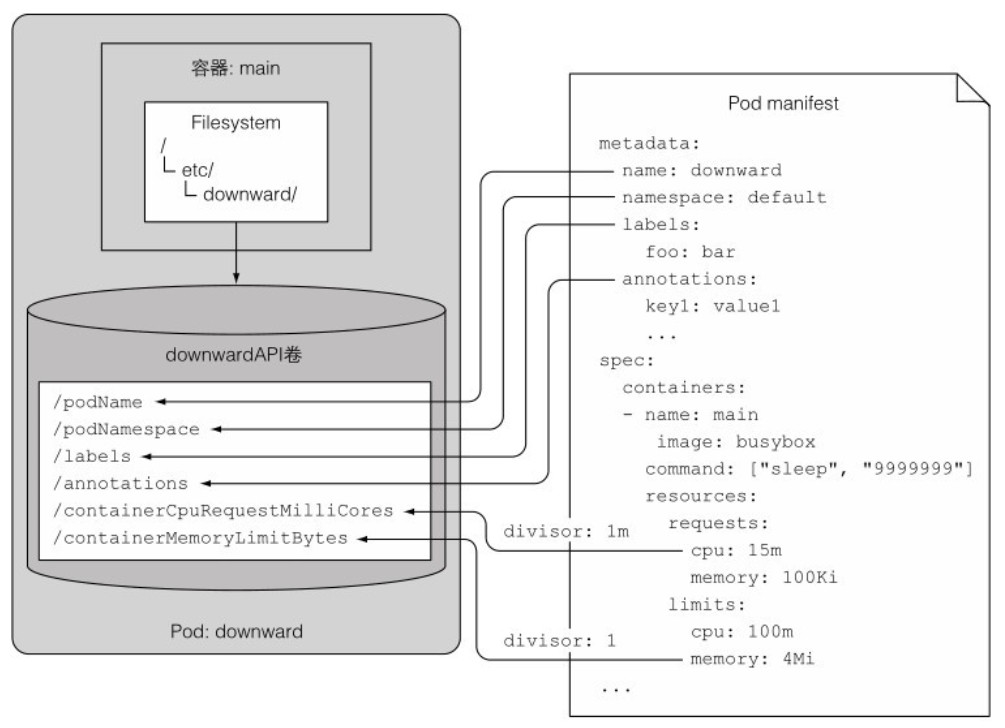
在容器中查看:
[root@server4-master ~]$ kubectl exec downward -- ls -lL /etc/downward
total 24
-rw-r--r-- 1 root root 337 Mar 15 22:12 annotations
-rw-r--r-- 1 root root 2 Mar 15 22:12 containerCpuRequestMilliCores
-rw-r--r-- 1 root root 7 Mar 15 22:12 containerMemoryLimitBytes
-rw-r--r-- 1 root root 9 Mar 15 22:12 labels
-rw-r--r-- 1 root root 8 Mar 15 22:12 podName
-rw-r--r-- 1 root root 7 Mar 15 22:12 podNamespace
[root@server4-master ~]$ kubectl exec downward -- cat /etc/downward/labels
foo="bar"当暴露容器级的元数据时,如资源限制或请求,必须指定容器名称。虽然方式稍微复杂一些,但可以将一个容器的资源字段传递给同一 Pod 中的另一个容器。
Kubernetes API
通过 Downward API 的方式获取的元数据相当有限。如果需要了解其他 Pod 或其他资源的信息,只能通过直接与 API 服务器进行交互。
K8s REST API
可以通过 kubectl cluster-info 命令获取服务器的地址,但无法直接使用 curl 进行交互:
[root@server4-master ~]$ kubectl cluster-info
Kubernetes control plane is running at https://192.168.2.204:6443
CoreDNS is running at https://192.168.2.204:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
[root@server4-master ~]$ curl https://192.168.2.204:6443 -k
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {
},
"status": "Failure",
"message": "forbidden: User \"system:anonymous\" cannot get path \"/\"",
"reason": "Forbidden",
"details": {
},
"code": 403当返回代码为 403 时表示未授权访问,可以通过启动代理 proxy 与服务器进行交互:
[root@server4-master ~]$ kubectl proxy
Starting to serve on 127.0.0.1:8001
[root@server4-master ~]$ curl 127.0.0.1:8001
{
"paths": [
"/.well-known/openid-configuration",
"/api",
"/api/v1",
"/apis/batch",
"/apis/batch/v1",
"/apis/batch/v1beta1",服务器会返回一组路径清单,即 REST endpoint 清单。这些路径对应了 apiVersion 定义的路径。以 Job 资源 API 组 /apis/batch 为例,下面列出了两个版本,其中常用的是 v1 版本:
[root@server4-master ~]$ curl 127.0.0.1:8001/apis/batch/v1
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "batch/v1",
"resources": [
{
"name": "cronjobs",
"singularName": "",
"namespaced": true,
"kind": "CronJob",
"verbs": [
"create",
"delete",
"deletecollection",
"get",
"list",
"patch",
"update",
"watch"
],
"shortNames": [
"cj"
],
"categories": [
"all"
],
"storageVersionHash": "sd5LIXh4Fjs="
},
{
"name": "cronjobs/status",
"singularName": "",
"namespaced": true,
"kind": "CronJob",
"verbs": [
"get",
"patch",
"update"
]
},
{
"name": "jobs",
"singularName": "",
"namespaced": true,
"kind": "Job",
"verbs": [
"create",
"delete",
"deletecollection",
"get",
"list",
"patch",
"update",
"watch"
],
"categories": [
"all"
],
"storageVersionHash": "mudhfqk/qZY="
},
{
"name": "jobs/status",
"singularName": "",
"namespaced": true,
"kind": "Job",
"verbs": [
"get",
"patch",
"update"
]
}
]
}在 resources 内包含了这个组中所有资源类型,每个资源对应可使用的操作(如创建、删除、获取等),以及其他一些资源的信息。其中,jobs/status 是用于专门修改状态(恢复、打补丁、修改)的资源。
可以向 /apis/batch/v1/jobs 路径发送 GET 请求,以获取集群中所有 Job 的清单:
[root@server4-master ~]$ curl 127.0.0.1:8001/apis/batch/v1/jobs
{
"kind": "JobList",
"apiVersion": "batch/v1",
"metadata": {
"resourceVersion": "656352"
},
"items": [
{
"metadata": {
"name": "batch-job",
"namespace": "default",
"uid": "dfcb1eda-55fc-4a30-ad7c-4769d5baebc4",
"resourceVersion": "656319",获取到的清单包括所有命名空间中的 Job。如果要返回指定的 Job,需要在请求 URL 中指定名称和命名空间。
[root@server4-master ~]$ curl 127.0.0.1:8001/apis/batch/v1/namespaces/default/jobs/batch-job
{
"kind": "Job",
"apiVersion": "batch/v1",
"metadata": {
"name": "batch-job",
"namespace": "default",通过这种方式获得的结果与执行 kubectl get job batch-job -o json 命令得到的结果相同。
从 Pod 内与 API 服务器交互
一般情况下,Pod 内没有可用的 kubectl,与 API 服务器进行交互需要解决认证问题。这里使用一个安装了 curl 的镜像,在容器内使用 curl 来测试与 API 服务器的交互结果:
[root@server4-master ~]$ vi curl.yaml
apiVersion: v1
kind: Pod
metadata:
name: curl
spec:
containers:
- name: main
image: curlimages/curl
command: ["sleep", "999999"]
[root@server4-master ~]$ kubectl create -f curl.yaml
pod/curl created
[root@server4-master ~]$ kubectl exec -it curl -- sh
/ $ env | grep KUBERNETES_SERVICE
KUBERNETES_SERVICE_PORT=443
KUBERNETES_SERVICE_PORT_HTTPS=443
KUBERNETES_SERVICE_HOST=10.96.0.1
/ $ curl https://kubernetes
curl: (60) SSL certificate problem: unable to get local issuer certificate
More details here: https://curl.se/docs/sslcerts.html在容器内查询 API 服务器的地址后,尝试访问时会提示证书问题。虽然可以通过 -k 选项来绕过 HTTPS 证书验证,但为了安全起见,应该检查证书以验证 API 服务器的身份,以避免中间人攻击,并防止将应用的验证凭证暴露给攻击者。
可以查看每个容器的 /var/run/secrets/kubernetes.io/serviceaccount 目录下默认的 Secret(token),其中包含的 ca.crt 可用于对 API 服务器证书进行签名。curl 允许使用 -cacert 选项来指定 CA 证书路径:
/ $ ls /var/run/secrets/kubernetes.io/serviceaccount
ca.crt namespace token
/ $ curl --cacert /var/run/secrets/kubernetes.io/serviceaccount/ca.crt https://kubernetes
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {
},
"status": "Failure",
"message": "forbidden: User \"system:anonymous\" cannot get path \"/\"",
"reason": "Forbidden",
"details": {
},
"code": 403
}这次 curl 验证通过了服务器的身份,但提示匿名用户没有查询权限。可以通过设置 CURL_CA_BUNDLE 环境变量来简化 curl 指定 CA 证书的选项:
/ $ export CURL_CA_BUNDLE=/var/run/secrets/kubernetes.io/serviceaccount/ca.crt接下来需要获取 API 服务器的授权,以进一步修改或删除部署在集群中的 API 对象。认证凭证可以使用默认的 token 来生成:
/ $ TOKEN=$(cat /var/run/secrets/kubernetes.io/serviceaccount/token)
/ $ curl -k -H "Authorization: Bearer $TOKEN" https://10.96.0.1 由于服务器使用 RBAC 机制,服务账户依然没有被授权(或部分授权)访问 API 服务器。可以通过修改角色绑定来临时赋予所有服务账户集群管理员权限:
[root@server4-master ~]$ kubectl create clusterrolebinding permissive-binding --clusterrole=cluster-admin --group=system:serviceaccounts
clusterrolebinding.rbac.authorization.k8s.io/permissive-binding createdSecret 卷中还包含一个命名空间的文件,其中包含了当前运行的 Pod 所在的命名空间。在请求中加入命名空间后再次访问,正常情况下会返回当前 Pod 所在命名空间的所有 Pod 清单:
/ $ NS=$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace)
/ $ curl -k -H "Authorization: Bearer $TOKEN" https://kubernetes/api/v1/namespaces/$NS/pods此时,Pod 与 API 服务器的交互已经没有阻碍,其他的 PUT 或 PATCH 请求同样可以操作。示意图如下:

总结一下 Pod 与 Kubernetes 交互的要点如下:
- 应用程序应验证 API 服务器的证书是否由受信任的证书机构签发,证书位于
ca.crt文件中。 - 应用程序应使用它在
token文件中持有的凭证来获取 API 服务器的授权。 - 当对 Pod 所在命名空间的 API 对象进行 CRUD(创建、读取、修改、删除)操作时,应使用
namespace文件来将命名空间信息传递到 API 服务器。
通过 ambassador 容器与 API 服务器交互
还有一种更简便与 API 服务器交互的方法,可以在 pod 中增加一个 ambassador 容器,其中运行着 kubectl proxy 命令,通过它来实现与 API 服务器的交互。如下图所示:

这种模式下,运行在主容器中的应用通过 HTTP 协议与 ambassador 连接,并由 ambassador 通过 HTTPS 协议来连接 API 服务器,对应用透明地处理安全问题,其同样使用默认凭证 Secret 卷中的文件来认证。
pod 配置在原先 curl 的基础上增加一个 kubectl-proxy 镜像,启动后进入到 curl 容器中的 shell 环境:
[root@server4-master ~]$ vi curl-am.yaml
apiVersion: v1
kind: Pod
metadata:
name: curl-am
spec:
containers:
- name: main
image: curlimages/curl
command: ["sleep", "999999"]
- name: ambassador
image: luksa/kubectl-proxy:1.6.2
[root@server4-master ~]$ kubectl create -f curl-am.yaml
pod/curl-am created
[root@server4-master ~]$ kubectl exec -it curl-am -c main -- sh
/ $ 接下来试着通过 ambassador 容器来连接 API 服务器。kubectl proxy 默认绑定 8001 端口,由于在同 pod 中可以直接访问本地回环地址:
/ $ curl localhost:8001
{
"paths": [
"/.well-known/openid-configuration",
"/api",
"/api/v1",
"/apis",
"/apis/",结果显示 ambassador 容器已经帮忙处理好了凭证和授权问题。
虽然 ambassador 容器已经足够简便,且能跨多个应用复用,但负面因素是需要运行额外的进程,消耗更多资源。
使用客户端与 API 服务器交互
如果应用仅仅需要在 API 服务器执行一些简单操作,可以使用一个标准的客户端库来执行简单的 HTTP 请求。但对于执行更复杂的 API 请求,使用某个已有的 K8s API 客户端库会更好。可以到 GitHub 社区查询到具体清单。
另外,如果选择的开发语言没有可用的客户端,可以使用 Swagger API 框架生成客户端库和文档。具体内容可访问官网。
控制器管理器
控制器主要工作是通过标签管理 pod,确保系统真实状态朝 API 服务器定义的期望状态收敛。
它们是 K8s 上的一类对象,包括 ReplicationController、ReplicaSet、Deployment、StatefulSet、Job 等。控制器的定义通常由期望的副本数量、pod 模板和标签选择器组成。
控制器工作
控制器通过 API 服务器监听资源(部署、服务等)变更,并执行相应操作。将实际状态调整为期望状态(资源 spec 部分定义)后,将新的实际状态写入资源的 status 部分。
控制器利用监听机制来订阅变更,但仍然会定期执行重列举操作来确保不会漏掉请求。
生命周期功能包括命名空间创建、事件垃圾回收、pod 终止相关垃圾回收、级联垃圾回收及节点垃圾回收等。
通过源码分析,控制器工作原理如下:
- 每个控制器一般有一个构造器,内部会创建一个 Informer,也就是监听器,每次 API 对象有更新就会被调用。
- 通常 Informer 会监听特定类型的资源变更事件。
- 控制器需要工作的时候会调用 worker() 方法,实际函数通常保存在一个叫 syncHandler 或类似字段里。该字段也在构造器里初始化,可以在那找到被调用函数名。
控制器类型
Kubernetes 中有多种类型的控制器,每种控制器都有不同的作用和特点。以下是一些常用的控制器类型。
ReplicationController 控制器
启动 ReplicationController(复制控制器)的控制器称为 ReplicationManager(复制管理器)。ReplicationManager 通过监听机制订阅可能影响复制集数量或符合条件的 pod 数量的变更事件。
任何变化都会触发 ReplicationController 控制器重新检查期望的复制集数量与实际数量,然后采取相应的操作。它不直接操作 pod,而是通过向 API 服务器创建新的 pod 清单,由 API 服务器通知调度器和 Kubelet 执行 pod 管理操作。其他控制器的工作流程也类似。
ReplicaSet、DaemonSet 和 Job 控制器
这些控制器的工作原理与 ReplicationController 控制器基本相同。
Deployment 控制器
Deployment 控制器负责同步 Deployment 的实际状态与对应的 Deployment API 对象的期望状态。每次修改 Deployment 对象后,控制器会进行滚动升级到新版本,通过创建一个 ReplicaSet(副本集)来调整 pod 的数量,直到升级完成。
StatefulSet 控制器
StatefulSet 控制器类似于 ReplicaSet 控制器,根据定义创建和管理 pod,但同时还会初始化和管理每个 pod 实例的持久卷声明。
Node 控制器
Node 控制器负责管理 Node 资源,描述集群的工作节点,并确保节点对象列表的正确性。同时监控每个节点的健康状态,删除不可达节点上的 pod。
Service 控制器
Service 控制器用于提供稳定的对 pod 的访问服务。
Endpoint 控制器
Endpoint 控制器负责维护端点列表。控制器同时监听 Service 和 pod,当 Service 或 pod 被添加或修改时,控制器会选择与 Service 中的 pod 选择器匹配的 pod,并将其 IP 和端口添加到 Endpoint 资源中。
Endpoint 对象是独立的对象,因此在需要时控制器会创建它,并在删除 Service 时一同删除。
Namespace 控制器
Namespace 控制器负责删除 Namespace 资源时,清除所有属于该命名空间的资源。
PersistentVolume 控制器
当用户创建 PersistentVolumeClaim(持久卷声明)时,控制器负责找到合适的 PersistentVolume(持久卷)与声明进行绑定。
查找的方式是保存一个有序的持久卷列表,按容量升序排列,返回列表中的第一个卷。
当用户删除持久卷声明时,控制器会解绑卷,并根据卷的回收策略进行处理。
调度器
调度器的角色比较简单,就是利用 API 服务器的监听机制等待新创建的 pod,然后给新建的 pod 分配节点。
调度器不会指示选中的节点运行 pod,而是通过 API 服务器更新 pod 的定义,然后由 API 服务器通知节点上的 Kubelet,告知该 pod 已被调度到此节点,并由目标节点上的 Kubelet 创建并运行 pod 的容器。
Kubernetes 还支持用户自定义调度器。
默认的调度算法
调度器的默认调度算法选择节点的操作可以分为两部分:首先过滤所有节点,找出可分配给 pod 的可用节点列表;然后对可用节点按优先级排序,找出最优节点。如果多个节点的优先级相同,则循环分配,确保 pod 平均分配。
查找可用节点
为了找出可用节点,调度器会对每个节点下发一组配置好的预选函数,检查节点信息:
- 节点是否能满足 pod 对硬件资源的请求;
- 节点是否耗尽资源;
- pod 是否有节点选择器;
- 节点是否符合 pod 中的节点选择器;
- pod 请求绑定的主机端口是否已被占用;
- pod 请求的存储卷是否能加载,是否可用;
- pod 是否能够容忍节点的污点;
- pod 是否定义了节点,以及 pod 的亲和性和反亲和性规则。
只有当所有的测试都通过时,节点才有资格被调度给 pod。
高级调度
默认情况下,属于同一服务和 ReplicaSet 的 pod 会分散在尽可能多的节点上,但可以通过定义 pod 的亲和性或反亲和性规则,强制 pod 在集群内分散或集中在一起。
多个调度器
可以在集群中运行多个调度器,然后在 pod 的属性中设置 schedulerName 属性来指定调度器来调度它。如果未设置此属性的 pod,则由默认调度器(default-scheduler)进行调度。
etcd
etcd 是一个分布式的键值存储数据库,Kubernetes 使用 etcd 来持久化存储集群状态和元数据。API 服务器是与 etcd 通信的唯一组件,所有其他组件通过 API 服务器间接地读写数据到 etcd。
etcdctl
要访问 etcd 数据库,需要在主节点上安装 etcdctl 客户端:
[root@server4-master ~]$ curl -L https://github.com/etcd-io/etcd/releases/download/v3.5.2/etcd-v3.5.2-linux-amd64.tar.gz -o etcd-v3.5.2-linux-amd64.tar.gz
[root@server4-master ~]$ tar -zxf etcd-v3.5.2-linux-amd64.tar.gz
[root@server4-master ~]$ cp etcd-v3.5.2-linux-amd64/etcdctl /usr/local/bin
[root@server4-master ~]$ etcdctl version
etcdctl version: 3.5.2
API version: 3.5设置好数据库地址、证书路径等到本地变量:
[root@server4-master ~]$ vi ~/.bashrc
export ETCDCTL_ENDPOINTS=https://127.0.0.1:2379
export ETCDCTL_CACERT=/etc/kubernetes/pki/etcd/ca.crt
export ETCDCTL_CERT=/etc/kubernetes/pki/etcd/healthcheck-client.crt
export ETCDCTL_KEY=/etc/kubernetes/pki/etcd/healthcheck-client.key
export ETCDCTL_API=3
[root@server4-master ~]$ source ~/.bashrc之后就可以直接通过命令来访问 etcd:
[root@server4-master ~]$ etcdctl get --keys-only --prefix /乐观并发控制
乐观并发控制,也称为乐观锁,指的是一段数据包含一个版本数字,而不是锁住该段数据阻止读写操作。
每当更新数据时,版本数就会增加。当更新数据时,会检查版本值是否在客户端读取数据时间和提交时间之间被增加过。如果有增加过,更新会被拒绝,客户端必须重新读取新数据,重新尝试更新。
当两个客户端尝试更新同一个数据条目时,只有第一个会成功。
所有的 Kubernetes 对象都包含一个 metadata.resourceVersion 字段用来保存版本数字。在更新对象时,客户端需要返回该值到 API 服务器,服务器检查版本值与 etcd 中存储的是否匹配。如果不匹配,服务器会拒绝更新。
资源储存
etcd 的版本 v2 和 v3 对资源存储格式有所不同。v2 版本将键存储在一个层级键空间中,使得键值对类似于文件系统的文件。每个键可以是一个目录,包含其他键,或者是一个常规键,对应一个值。v3 版本不支持目录,但由于键格式保持不变,键可以包含斜杠,仍然可以将它们组织成目录结构。
Kubernetes 将所有数据存储到 etcd 的 /registry 下,可以使用 etcdctl 来查询:
[root@server4-master ~]$ etcdctl get --keys-only --prefix /registry | less
/registry/apiextensions.k8s.io/customresourcedefinitions/apiservers.operator.tigera.io
/registry/apiextensions.k8s.io/customresourcedefinitions/bgpconfigurations.crd.projectcalico.org
/registry/apiextensions.k8s.io/customresourcedefinitions/bgppeers.crd.projectcalico.org
/registry/apiextensions.k8s.io/customresourcedefinitions/blockaffinities.crd.projectcalico.org会发现键与资源名称相对应。还可以单独查看特定命名空间下的 Pod 列表:
[root@server4-master ~]$ etcdctl get --keys-only --prefix /registry/pods/default
/registry/pods/default/kubia-0
/registry/pods/default/kubia-1
/registry/pods/default/kubia-2如果要查看特定 Pod 在 etcd 中存储的内容,可以执行以下命令:
[root@server4-master ~]$ etcdctl get /registry/pods/default/kubia-1
kube-controller-managerUpdatevFieldsV1:f:metadata":{"f:generateName":{},"f:labels":{".":{},"f:app":{},"f:controller-revision-hash":{},"f:statefulset.kubernetes.io/pod-name":{}},"f:ownerReferences":{".":{},"k:{\"uid\":\"4142df85-4fb1-4b09-84ab-24ad2d1c309e\"}":{}}},"f:spec":{"f:containers":{"k:{\"name\":\"kubia\"}":{".":{},"f:image":{},"f:imagePullPolicy":{},"f:name":{},"f:ports":{".":{},"k:{\"containerPort\":8080,\"protocol\":\"TCP\"}":{".":{},"f:containerPort":{},"f:name":{},"f:protocol":{}}},"f:resources":{},"f:terminati这将返回 JSON 格式的 Pod 定义。
etcd 集群
为了保证高可用性,etcd 集群通常会部署多个(奇数个)etcd 实例。etcd 使用 Raft 一致性算法来确保系统达到一致的实际状态。
该算法要求大部分节点参与才能进行下一个状态的提交,否则集群将分裂成两个不互联的节点组。如果一个组的成员数超过另一个组,大组可以更改集群状态,而小组则不能。当两个组重新恢复连接时,小组的节点会将状态更新为大组节点的状态。下图展示了这个过程:
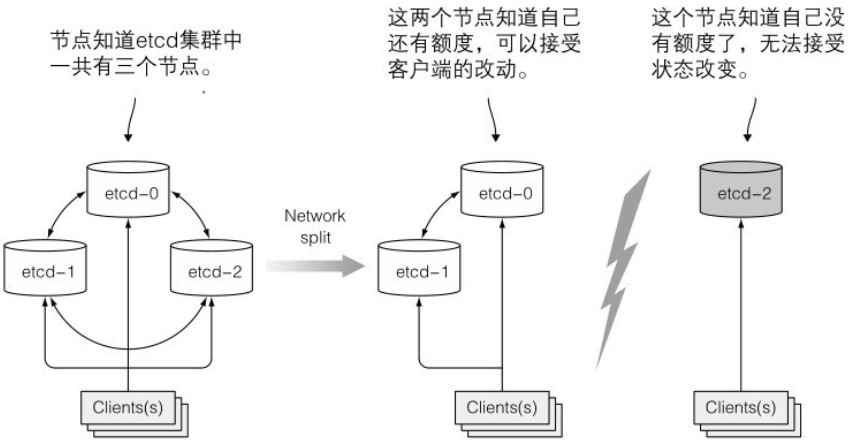
Kubelet
Kubelet 是 Kubernetes 中的一个核心组件,它运行在每个节点上,负责管理节点上的容器和与主控组件的通信。
工作内容
Kubelet 负责所有运行在工作节点上的内容组件。
其工作内容是:
- 在 API 服务器中创建一个 Node 资源来注册 Kubelet 所在节点。
- 持续监控 API 服务器是否将该节点分配给 pod。
- 告知节点上的容器运行时拉取镜像,启动容器。
- 持续监控运行的容器,向 API 服务器报告它们的状态、事件和资源消耗。
- 在 pod 被从 API 服务器删除时,Kubelet 终止容器并通知服务器 pod 已被终止。
运行静态 pod
Kubelet 还可以基于本地指定目录下的 pod 清单来运行 pod,主要用于运行容器化版本的控制面板组件。
静态 pod 总由 Kubelet 创建在 Kubelet 所在的 Node 上运行,由 Kubelet 管理。不能通过 API Server 进行管理,不能与控制器进行关联,Kubelet 也无法对它们进行健康检查。
启动静态 pod 需要设置 Kubelet 的启动参数 --config,指定需要监控的配置文件所在目录,并根据 YAML 进行创建操作。例如配置 --config=/etc/kubelet.d/,然后重启 Kubelet 服务。在目录下写入 static-web.yaml 文件:
[root@server4-master ~]$ vi static-web.yaml
apiVersion: v1
kind: Pod
metadata:
name: static-web
labels:
name: static-web
namespace: default
spec:
containers:
- name: static-web
image: nginx
ports:
- name: web
containerPort: 80等待一段时间可以看到 pod 被创建出来。假如在 Master 节点删除 pod,会使其变为 Pending 状态且不会被删除。
还可以通过设置 Kubelet 的启动参数 --manifest-url,Kubelet 将会定期从指定 URL 地址下载定义文件创建 pod。
Proxy
Proxy 是一种核心组件,它用于在集群内部提供网络代理服务。它负责处理集群内部各个节点上的网络请求,并将其转发到适当的目标。
代理作用
除了 Kubelet,每个工作节点都会运行 kube-proxy,用于确保客户端通过 API 服务器对服务 IP 和端口的连接最终能够到达支持服务(或其他非 Pod 服务终端)的某个 Pod。
如果一个服务由多个 Pod 支持,那么代理将对 Pod 进行负载均衡。
代理实现
kube-proxy 最初被称为 userspace 代理,它利用实际的服务器集成接收连接,并将其代理给 Pod。为了拦截发往服务 IP 的连接,代理配置了 iptables 规则,将连接重定向到代理服务器。如下图所示:
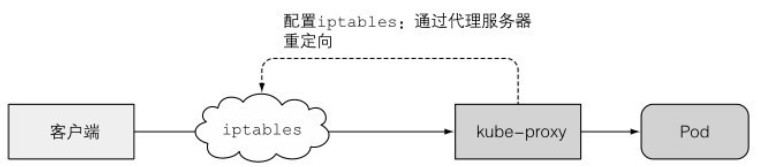
当前的 kube-proxy 仅通过 iptables 或 ipvs 规则将数据包重定向到一个随机选择的后端 Pod,不再需要一个实际的代理服务器。这种模式也被称为 iptables 代理模式。如下图所示:
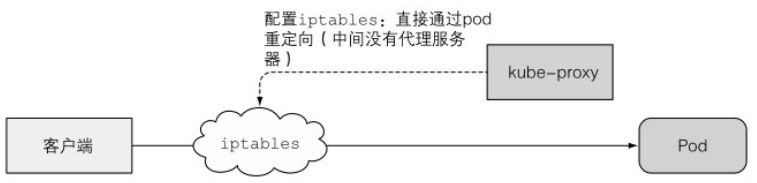
这两种模式的主要区别在于数据包是否传递给 kube-proxy、是否需要在用户空间进行处理,或者数据包是否仅在内核空间进行处理。这两种模式的性能有很大差异。
另一个区别是,userspace 代理模式使用轮询模式对连接进行负载均衡,而 iptables 代理模式随机选择 Pod,在客户端连接较少时可能无法平均分配流量。
其他组件
除了 Kubernetes 核心组件之外,还有许多第三方组件可以扩展和增强 Kubernetes 的功能。这些组件通常被称为“附加组件”或“扩展组件”,它们提供了各种功能,如网络、存储、监控、日志记录等。
以下是一些常见的第三方组件,可以根据需求选择和部署:
- 容器网络接口(Container Networking Interface,CNI):CNI 是一个规范,用于定义容器和宿主机之间的网络连接。它允许不同的网络插件与 Kubernetes 集成,并提供容器之间的网络通信。
- 存储插件:存储插件用于将外部存储系统与 Kubernetes 集群集成。这些插件可以提供持久化存储解决方案,如网络存储、分布式存储和块存储。
- 监控和日志组件:监控和日志组件用于收集、分析和可视化 Kubernetes 集群的监控数据和日志。一些常见的监控和日志工具包括 Prometheus、Grafana、Elasticsearch 和 Fluentd。
- Ingress 控制器:Ingress 控制器是一个负载均衡器,用于将外部流量路由到 Kubernetes 集群内部的服务。它可以提供 HTTP 和 HTTPS 等应用层协议的路由功能。
- 安全组件:安全组件用于增强 Kubernetes 集群的安全性。它们可以提供认证、授权、身份管理和访问控制等功能,以保护集群中的资源和敏感数据。
DNS
集群中所有的 Pod 默认配置使用集群内部的 DNS 服务器。Pod 可以通过名称轻松查询集群内的服务,甚至是无头服务的 Pod IP 地址。
DNS 服务的 Pod 通过 kube-dns 服务对外暴露,DNS 服务的 IP 地址在集群中每个容器的 /etc/resolv.conf 文件中都有定义。
kube-dns Pod 利用 API 服务器的监控机制来订阅 Service 和 Endpoint 的变动,以及 DNS 记录的变更,从而确保客户端始终获取到最新的 DNS 信息。
Ingress 控制器
Ingress 控制器运行一个反向代理服务器,类似于 Nginx。它根据集群中定义的 Ingress、Service 和 Endpoint 资源来配置该控制器。因此,需要订阅这些资源,并在发生变化时更新代理服务器的配置。
尽管 Ingress 资源的定义指向一个 Service,但是 Ingress 控制器会直接将流量转发到服务的 Pod,而不经过服务的 IP。当外部客户端通过 Ingress 控制器连接时,会保存客户端的 IP,而 Service 本身无法实现这一点。