K8s 控制器资源
ReplicationController
以下简称 RC。 可以使用 kubectl api-resources 命令查看所有缩写。
ReplicationController 用于确保 Pod 始终处于运行状态。它主要通过 Pod 标签来控制副本数量。RC 是最初用于复制和重新调度节点的组件,后来被 ReplicaSet 取代,不推荐再使用。
RC 主要由三个部分组成:
- 标签选择器(Label Selector):用于确定 RC 作用域中的 Pod。
- 副本个数(Replica Count):指定应该运行的 Pod 数量。
- Pod 模板(Pod Template):用于创建新的 Pod 副本。
RC 的配置可以随时修改:
- 修改副本数量会立即生效。
- 更改标签选择器和 Pod 模板对正在运行的 Pod 没有影响,只会使现有的 Pod 脱离 RC 的控制范围。
- 修改模板仅影响由此 RC 创建的新 Pod。
- 如果更改了一个 Pod 的标签,它将不再由 RC 管理,RC 将自动启动一个新的 Pod 来替代它。
创建 RC
创建一个最简化的 RC 配置,运行 3 个 Pod 副本,配置如下:
[root@server4-master ~]$ vi kubia-rc.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: kubia
spec:
replicas: 3
selector:
app: kubia
template:
metadata:
labels:
app: kubia
spec:
containers:
- name: kubia
image: luksa/kubia
ports:
- containerPort: 8080
[root@server4-master ~]$ kubectl create -f kubia-rc.yaml
replicationcontroller/kubia created标签选择器需要与 Pod 的 labels 标签匹配,否则 RC 会不断启动新的容器。如果不指定选择器 selector,RC 会根据 Pod 模板中的标签自动配置。
运行后,Kubernetes 会创建一个名为 “kubia” 的新 RC,并始终运行 3 个实例。如果没有足够的 Pod,RC 会根据模板创建新的 Pod。下面手动删除一个 Pod,RC 会立即重新创建一个新的容器:
[root@server4-master ~]$ kubectl delete po kubia-wtlrp
pod "kubia-wtlrp" deleted
[root@server4-master ~]$ kubectl get po
NAME READY STATUS RESTARTS AGE
kubia-2vpxd 1/1 Running 0 105s
kubia-9fqql 1/1 Running 0 105s
kubia-slltr 1/1 Running 0 22s
kubia-wtlrp 1/1 Terminating 0 105s如果有节点故障,RC 会在新的节点上启动原先故障节点上的 Pod,之后即使节点故障恢复,Pod 也不会再迁移回故障节点上。
查看 RC
查询当前运行的所有 RC:
[root@server4-master ~]$ kubectl get rc
NAME DESIRED CURRENT READY AGE
kubia 3 3 3 9m37s查询具体 RC 的信息同样使用 kubectl describe 命令:
[root@server4-master ~]$ kubectl describe rc kubia
Name: kubia
Namespace: default
Selector: app=kubia
Labels: app=kubia
Annotations: <none>
Replicas: 3 current / 3 desired
P Status: 3 Running / 0 Waiting / 0 Succeeded / 0 Failed修改模板
可以通过 kubectl edit rc 命令来修改 RC 的 Pod 模板,例如修改模板中的标签选择器和副本数:
[root@server4-master ~]$ kubectl edit rc kubia
spec:
replicas: 2
selector:
app: kubia1
template:
metadata:
labels:
app: kubia1
"/tmp/kubectl-edit-2608748675.yaml" 46L, 1157C written
replicationcontroller/kubia edited查看 Pod 和 Label,发现共有 5 个 Pod,新旧标签同时存在:
[root@server4-master ~]$ kubectl get po --show-labels
NAME READY STATUS RESTARTS AGE LABELS
kubia-2c44j 1/1 Running 0 56s app=kubia1
kubia-2vpxd 1/1 Running 0 40m app=kubia
kubia-9fqql 1/1 Running 0 40m app=kubia
kubia-ggk2j 1/1 Running 0 56s app=kubia1
kubia-slltr 1/1 Running 0 38m app=kubia水平缩放
使用 scale 命令可以修改 RC 配置中的 spec.replicas 字段的数值,实现扩缩容效果:
[root@server4-master ~]$ kubectl scale rc kubia --replicas=1
replicationcontroller/kubia scaled
[root@server4-master ~]$ kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
kubia-2c44j 1/1 Running 0 5m18s app=kubia1
kubia-ggk2j 1/1 Terminating 0 5m18s app=kubia1删除 RC
当使用 delete 命令删除 RC 时,Pod 也会被删除。可以指定 --cascade=orphan 选项来删除 RC 同时保持 Pod 运行:
[root@server4-master ~]$ kubectl delete rc kubia --cascade=orphan
replicationcontroller "kubia" deleted之后可以通过标签选择器创建新的 RC 或 ReplicaSet 将它们再次管理起来。
ReplicaSet
以下简称 RS。RS 和 RC 都是依赖 Pod 标签选择器来进行控制。
RS 的行为和用法与 RC 几乎完全相同。与 RC 相比,RS 的选择器还允许进行反向选择,或者通过标签键来选择 Pod。例如,选择所有带有 env 标签的 Pod(env=*)。
通常情况下,不会直接创建 RS 对象,而是通过创建 Deployment 资源时自动创建。Deployment 通过 RS 来管理多个 Pod 副本。
创建 RS
创建一个 YAML 配置文件并发布。与 RC 配置不同的是 apiVersion 版本、kind 类型和标签选择器的样式:
[root@server4-master ~]$ vi kubia-rs.yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: kubia
spec:
replicas: 3
selector:
matchLabels:
app: kubia
template:
metadata:
labels:
app: kubia
spec:
containers:
- name: kubia
image: luksa/kubia
ports:
- name: http
containerPort: 80
[root@server4-master ~]$ kubectl create -f kubia-rs.yaml
replicaset.apps/kubia created标签选择
标签选择器和 Pod 中使用的方式相同,只是语法略有不同。例如,通过 matchLabels 来匹配单个标签:
[root@server4-master ~]$ vi kubia-rs.yaml
spec:
selector:
matchLabels:
app: kubia通过 matchExpressions 表达式同时选择两个不同 app 值的标签:
[root@server4-master ~]$ vi kubia-rs.yaml
spec:
selector:
matchExpressions:
- key: app
operator: In
values:
- kubia
- kubia1operator 还可以使用其他运算符:NotIn(不在列表中)、Exists(匹配 Key)、DoesNotExist(反向匹配 Key)。
如果指定了多个表达式,所有表达式的匹配结果都必须为 true 才能使选择器与 Pod 匹配。
如果同时使用 matchLabels 和 matchExpressions,则所有标签都必须匹配。
Deployment
最常用的控制器,可以管理多个副本的 pod 并确保它们按照预期状态运行。
Deployment 是一种更高级的资源,用于部署应用程序并以声明的方式升级应用。创建 Deployment 资源时,会同时创建 ReplicaSet(RS)资源,实际上是由 RS 创建和管理 pod。Deployment 的主要职责是处理应用程序升级时两个版本的控制器之间的关系。
下面简称为 Deploy。
创建 Deploy
创建一个 Deploy 的过程与创建 ReplicaController(RC)的声明基本相同,只是 Deploy 的声明中包含了额外的部署策略字段。由于 Deploy 可以同时管理多个版本的 pod,因此在 Deploy 的名称中不需要添加版本号:
[root@server4-master ~]$ vi kubia-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kubia
spec:
replicas: 3
selector:
matchLabels:
app: kubia
template:
metadata:
name: kubia
labels:
app: kubia
spec:
containers:
- image: luksa/kubia:v1
name: nodejs
---
apiVersion: v1
kind: Service
metadata:
name: kubia
spec:
type: NodePort
selector:
app: kubia
ports:
- port: 80
targetPort: 8080
nodePort: 30002创建 Deploy 时加入 --record 选项,可以记录 CHANGE-CAUSE 信息,即声明文件中的注解字段:
[root@server4-master ~]$ kubectl create -f kubia-deploy.yaml --record
Flag --record has been deprecated, --record will be removed in the future
deployment.apps/kubia created
service/kubia created使用 kubectl rollout 命令可以查询 Deploy 的部署状态:
[root@server4-master ~]$ kubectl rollout status deployment kubia
deployment "kubia" successfully rolled out
[root@server4-master ~]$ kubectl get all
NAME READY STATUS RESTARTS AGE
pod/kubia-74967b5695-5s68q 1/1 Running 0 10s
pod/kubia-74967b5695-8cxtb 1/1 Running 0 10s
pod/kubia-74967b5695-bwzb9 1/1 Running 0 10s
pod/kubia-74967b5695-jkcjl 0/1 Terminating 0 2m55s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 133d
service/kubia NodePort 10.101.57.66 <none> 80:30002/TCP 10s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/kubia 3/3 3 3 10s
NAME DESIRED CURRENT READY AGE
replicaset.apps/kubia-74967b5695 3 3 3 10s新建的 pod 名字中间会有一串数字,这是 pod 模板的哈希值。由 Deploy 创建的 ReplicaSet 控制器也带有相同的哈希值。这样 Deploy 就能够对应和管理一个版本的 pod 模板。
通过 30002 端口访问服务来测试 pod 的工作状态:
[root@server4-master ~]$ curl localhost:30002
This is v1 running in pod kubia-74967b5695-5s68q升级 Deploy
Deploy 默认的升级策略是执行滚动更新(RollingUpdate)。另一种策略是 Recreate,它会一次性删除所有旧版本的 pod,然后创建新的 pod。
通过 patch 命令修改单个或少量资源属性非常有用,但是更改 Deploy 的自有属性不会触发 pod 的任何更新。可以通过设置一个时间来减慢滚动更新的速度:
[root@server4-master ~]$ kubectl patch deploy kubia -p '{"spec": {"minReadySeconds": 10}}'
deployment.apps/kubia patched采用 set image 命令来更改包含容器资源中的镜像:
[root@server4-master ~]$ kubectl set image deployment kubia nodejs=luksa/kubia:v2
deployment.apps/kubia image updated通过 describe 命令查询可以查看 Deploy 的升级方式,和 ReplicaController(RC)滚动升级类似,先增加新版本的 pod,缩减旧版本的 pod,最后完成升级:
[root@server4-master ~]$ kubectl get all
NAME READY STATUS RESTARTS AGE
pod/kubia-74967b5695-5s68q 1/1 Running 0 3m40s
pod/kubia-74967b5695-8cxtb 1/1 Terminating 0 3m40s
pod/kubia-74967b5695-bwzb9 1/1 Running 0 3m40s
pod/kubia-bcf9bb974-9kb8x 1/1 Running 0 3s
pod/kubia-bcf9bb974-bqwng 1/1 Running 0 21s如下图所示,整个升级过程由运行在 Kubernetes 上的一个控制器处理和完成,简单又可靠:
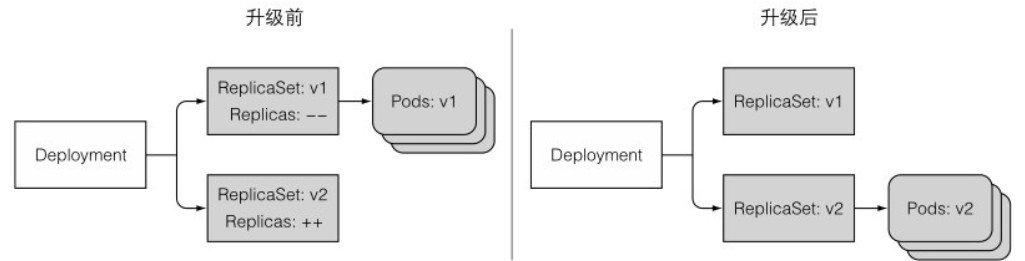
如果 Deployment 中的 pod 模板引用了一个 ConfigMap(Secret),那么更改 ConfigMap 资源不会触发升级操作。需要创建一个新的 ConfigMap 并修改 pod 模板引用新的 ConfigMap。
回滚升级
如果升级的版本存在问题,可以自动停止升级。首先将应用升级到有错误的版本,在第 5 个请求之后会返回内部服务器错误,即 HTTP 状态码 500:
[root@server4-master ~]$ kubectl set image deploy kubia nodejs=luksa/kubia:v3
deployment.apps/kubia image updated
[root@server4-master ~]$ kubectl rollout status deploy kubia
Waiting for deployment "kubia" rollout to finish: 1 out of 3 new replicas have been updated...
Waiting for deployment "kubia" rollout to finish: 2 out of 3 new replicas have been updated...
Waiting for deployment "kubia" rollout to finish: 1 old replicas are pending termination...
deployment "kubia" successfully rolled out可以使用 rollout undo 命令回滚到上一个版本:
[root@server4-master ~]$ kubectl rollout undo deploy kubia
deployment.apps/kubia rolled backundo 命令也可以在滚动升级过程中运行,并直接停止升级回退到旧版本。
最后,通过 rollout history 来显示升级版本的历史记录,可以使用 --revision=1 指定版本号:
[root@server4-master ~]$ kubectl rollout history deployment kubia
deployment.apps/kubia
REVISION CHANGE-CAUSE
1 kubectl create --filename=kubia-deploy.yaml --record=true
3 kubectl create --filename=kubia-deploy.yaml --record=true
4 kubectl create --filename=kubia-deploy.yaml --record=true滚动升级成功后,旧版本的 ReplicaSet 不会被删除,Kubernetes 会保留完整的版本修改历史。历史记录保留数目默认为 2,由 Deploy 的 revisionHistoryLimit 属性值来限制,更早的 ReplicaSet 会被删除。
因此,可以通过 undo 命令指定一个特定版本号,回滚到指定的版本:
[root@server4-master ~]$ kubectl rollout undo deploy kubia --to-revision=1
deployment.apps/kubia rolled back--to-revision 参数对应着历史记录上的版本。如果手动删除了遗留的 ReplicaSet,将导致历史版本记录丢失,无法进行回滚。另外,扩容操作不会创建新的版本。
滚动升级策略属性
可以通过修改 Deploy 配置文件中的 spec.strategy.rollingUpdate 来调整滚动升级策略的两个属性:
-
maxSurge(最大超出数量)该属性决定了在 Deploy 配置中所期望的副本数之外,允许超出的 Pod 实例数量。默认值为 25%。例如,如果期望副本数为 4,那么在滚动升级期间,最多会运行 5 个 Pod 实例。将百分数转换为绝对值时会进行四舍五入。也可以直接指定绝对值。
-
maxUnavailable(最大不可用数量)该属性决定了在滚动升级期间,相对于期望副本数允许的不可用 Pod 实例数量。默认值为 25%,表示可用的 Pod 实例数量不能低于期望副本数的 75%。例如,如果期望副本数为 4,那么只能有一个 Pod 处于不可用状态。也可以使用绝对值进行设定。
假设当前运行的副本数量为 3。当设置 maxSurge=1,maxUnavailable=0 时,表示需要始终保持 3 个可用的副本,升级过程中最多运行 4 个副本数量。每次启动 1 个新副本,新副本正常运行后,删除 1 个旧副本,直到所有旧副本都被替换掉。整个过程的示意图如下所示:
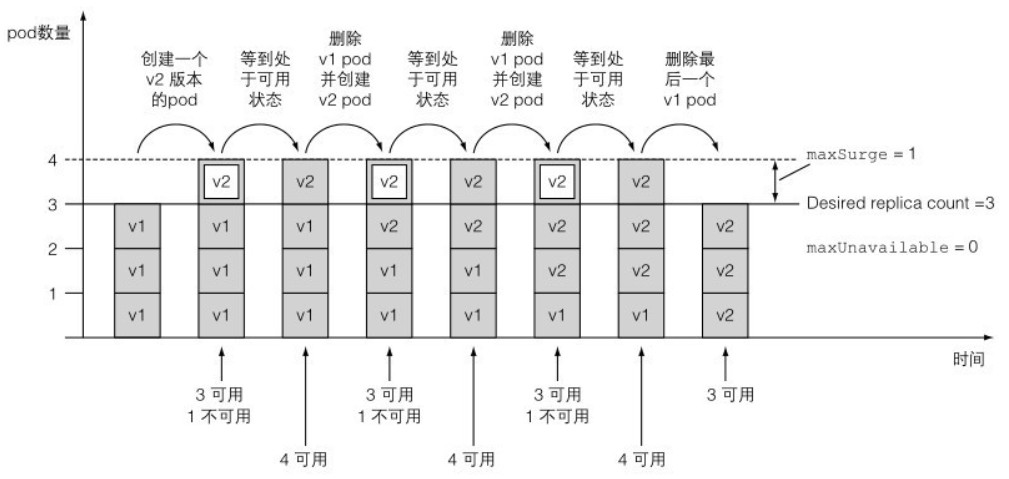
对于 extensions/v1beta1 版本的 Deploy,使用不同的默认值,两个参数都被设置为 1,表示允许 1 个副本处于不可用状态,升级过程中最多运行 4 个副本数量。首先删除 1 个旧副本,启动 2 个新副本,新副本正常运行后,继续删除 1 个旧副本并启动 1 个新副本,直到所有旧副本都被替换掉。整个过程的示意图如下所示:
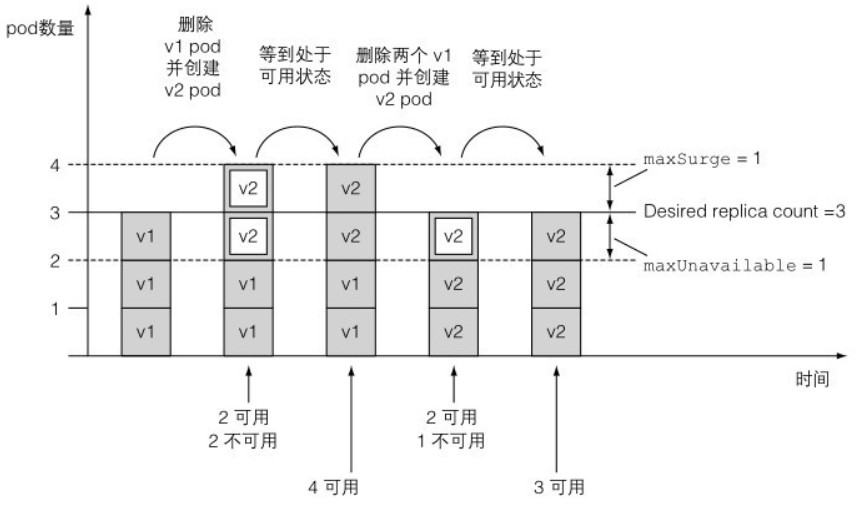
暂停滚动更新
可以使用 rollout pause 命令在更新过程中暂停升级:
[root@server4-master ~]$ kubectl set image deploy kubia nodejs=luksa/kubia:v4
deployment.apps/kubia image updated
[root@server4-master ~]$ kubectl rollout pause deploy kubia
deployment.apps/kubia paused在此时应用程序处于一个新版本的 Pod 加上三个旧版本的 Pod 的混合运行状态下,部分请求将被切换到新的 Pod 上。通过这种方式,只有部分用户会访问到新版本,相当于运行了一个金丝雀版本。在验证新版本是否正常工作后,可以继续升级剩余的 Pod 或回滚到上一个版本。
可以使用 && 符号将两个命令连接起来:
[root@server4-master ~]$ kubectl set image deploy kubia nodejs=luksa/kubia:v1 && kubectl rollout pause deploy kubia
deployment.apps/kubia image updated
deployment.apps/kubia paused
[root@server4-master ~]$ kubectl get all
NAME READY STATUS RESTARTS AGE
pod/kubia-74967b5695-ckpf9 1/1 Running 0 53s
pod/kubia-7bddb8bfc7-fjkkg 1/1 Running 0 2m
pod/kubia-7bddb8bfc7-hnjh4 1/1 Running 0 2m12s
pod/kubia-7bddb8bfc7-wtt8g 1/1 Running 0 108s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 133d
service/kubia NodePort 10.101.57.66 <none> 80:30002/TCP 37m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/kubia 4/3 1 4 37m
NAME DESIRED CURRENT READY AGE
replicaset.apps/kubia-555774bf68 0 0 0 9m58s
replicaset.apps/kubia-74967b5695 1 1 1 37m
replicaset.apps/kubia-7bddb8bfc7 3 3 3 31m
replicaset.apps/kubia-bcf9bb974 0 0 0 34m
[root@server4-master ~]$ curl localhost:30002
This is v3 running in pod kubia-7bddb8bfc7-wtt8g
[root@server4-master ~]$ curl localhost:30002
This is v1 running in pod kubia-74967b5695-ckpf9滚动升级的进度无法控制,因此进行金丝雀发布的正确方式是使用两个不同的 Deploy,并同时调整它们对应的 Pod 数量。
恢复滚动升级
在暂停升级期间,撤销命令不起作用。在恢复升级后才能进行撤销操作。可以使用 rollout resume 命令来恢复升级:
[root@server4-master ~]$ kubectl rollout resume deploy kubia
deployment.apps/kubia resumed
[root@server4-master ~]$ kubectl rollout undo deploy kubia --to-revision=3
deployment.apps/kubia rolled back暂停部署还可以阻止更新 Deploy 后自动触发的滚动升级过程。可以对 Deployment 进行多次更改,并在完成所有更改后再恢复滚动升级,一旦所有更改完成,则恢复更新过程。
配置就绪探针
使用 minReadySeconds 属性来设置新的 Pod 运行多久后才将其标记为可用。当所有容器的就绪探针返回成功时,Pod 就被标记为就绪状态。如果一个新的 Pod 运行出错,并且在 minReadySeconds 时间内其就绪探针失败,那么新版本的滚动升级将被阻止。一般会将 minReadySeconds 设置为较高的值,以确保 Pod 在真正接收实际流量后可以持续保持就绪状态。
使用之前会报错的 v3 镜像来测试就绪探针的作用:
[root@server4-master ~]$ vi kubia-v3.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kubia
spec:
replicas: 3
selector:
matchLabels:
app: kubia
minReadySeconds: 10
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
type: RollingUpdate
template:
metadata:
name: kubia
labels:
app: kubia
spec:
containers:
- image: luksa/kubia:v3
name: nodejs
readinessProbe:
periodSeconds: 1
httpGet:
path: /
port: 8080通过将 maxUnavailable 的值设置为 0,确保在升级过程中 Pod 逐个被替换。就绪探针的 GET 请求每秒执行一次,在第 6 秒开始报错。使用 apply 命令升级 Deployment 时,不仅会更新镜像,还会添加就绪探针以及其他参数:
[root@server4-master ~]$ kubectl apply -f kubia-v3.yaml
Warning: resource deployments/kubia is missing the kubectl.kubernetes.io/last-applied-configuration annotation which is required by kubectl apply. kubectl apply should only be used on resources created declaratively by either kubectl create --save-config or kubectl apply. The missing annotation will be patched automatically.
deployment.apps/kubia configured观察 curl 的输出,可以看到流量并没有转发到 v3 版本的 Pod 上,因为新的 Pod 尚未就绪,被从 Service 的 endpoint 中移除:
[root@server4-master ~]$ curl localhost:30002
This is v1 running in pod kubia-74967b5695-8kmxn
[root@server4-master ~]$ curl localhost:30002
This is v1 running in pod kubia-74967b5695-ckpf9
[root@server4-master ~]$ curl localhost:30002
This is v1 running in pod kubia-74967b5695-ls2z2
[root@server4-master ~]$ kubectl get po
NAME READY STATUS RESTARTS AGE
kubia-67d49c55dd-wcnwd 0/1 Running 0 60s
kubia-74967b5695-8kmxn 1/1 Running 0 4m40s
kubia-74967b5695-ckpf9 1/1 Running 0 10m
kubia-74967b5695-ls2z2 1/1 Running 0 4m28s
[root@server4-master ~]$ kubectl describe po kubia-67d49c55dd-wcnwd
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning Unhealthy 2m51s (x22 over 3m11s) kubelet Readiness probe failed: HTTP probe failed with statuscode: 500之后,升级一直处于进行中的状态,因为 maxUnavailable 为 0,所以既不会创建新的 Pod,也不会删除任何原始的 Pod。整个流程如下图所示:
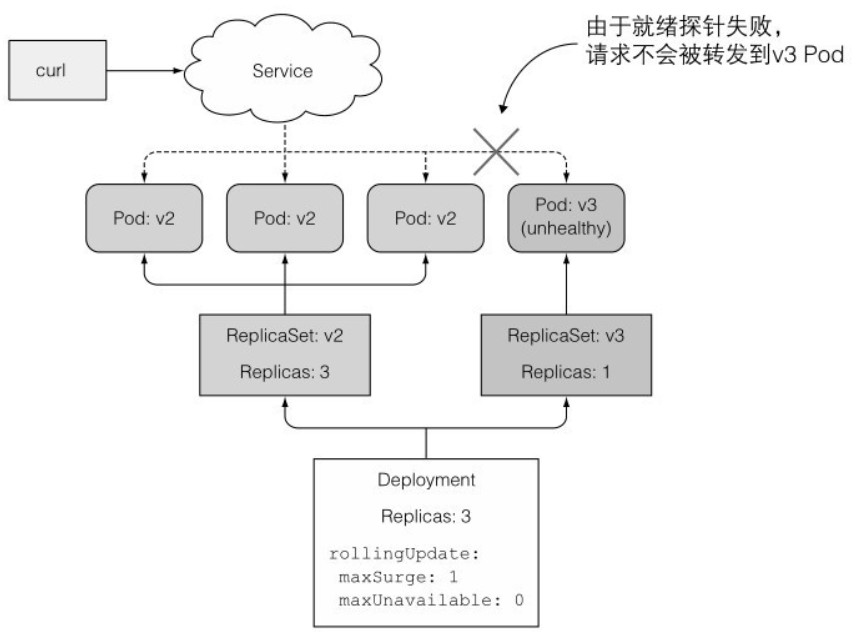
如果没有正确设置 minReadySeconds,一旦有一个就绪探针调用成功,就会认为新的 Pod 已经可用。因此,建议将时间设定得较长一些。
默认情况下,滚动升级如果在 10 分钟内无法完成,将被视为失败。可以通过 spec.progressDeadlineSeconds 来设置此时限:
[root@server4-master ~]$ kubectl describe deploy kubia
Name: kubia
Namespace: default
Replicas: 3 desired | 1 updated | 4 total | 3 available | 1 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 10
RollingUpdateStrategy: 0 max unavailable, 1 max surge
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing False ProgressDeadlineExceeded
OldReplicaSets: kubia-74967b5695 (3/3 replicas created)
NewReplicaSet: kubia-67d49c55dd (1/1 replicas created)如果滚动升级卡住,只能通过 rollout undo 命令来取消滚动升级。
StatefulSet
StatefulSet 用于确保每个 Pod 副本在整个生命周期中具有相同的名称、网络标识和状态,而其他控制器则不提供此功能。同时,StatefulSet 会确保副本按照固定的顺序启动、更新或删除。
下面简称 STS。
应用状态
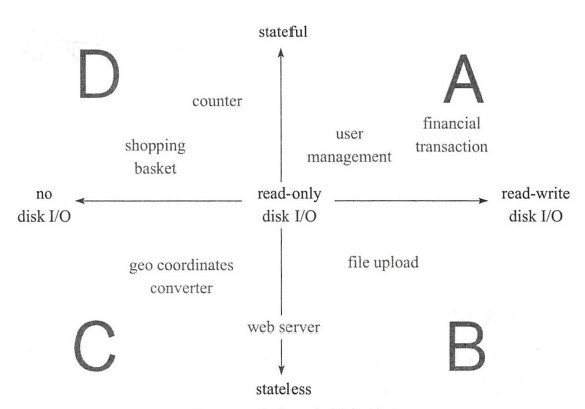
可以通过状态和储存两个概念正交于坐标系中,得到四种应用程序类型:
- 象限 A 中是那些具有读写磁盘需求的有状态应用程序,例如各种 RDBMS 储存系统、分布式储存系统 Redis Cluster、MongoDB、ZooKeeper、Cassandra 等。
- 象限 B 包含两类应用程序,一类是具有读写磁盘需求的无状态应用程序,另一类是仅需读取权限的无状态应用,比如 Web 服务程序。
- 象限 C 中是无磁盘访问需求的无状态应用程序。
- 象限 D 中是无磁盘访问需求的有状态应用程序,例如淘宝的购物车系统。
有状态服务
在 Kubernetes 中,Pod 的管理对象包括 ReplicationController(RC)、ReplicaSet(RS)、Deployment(Deploy)、DaemonSet(DS)和 Job 等,都是面向无状态的服务。然而,许多服务是有状态的,例如 MySQL 集群、MongoDB 集群、Akka 集群等。这些集群具有一些共同点:
-
每个节点都有固定的身份 ID,通过该 ID 进行相互发现和通信;
-
集群的规模相对固定,不能随意变动;
-
集群中的每个节点都具有状态,通常会将数据持久化到永久存储中;
-
如果磁盘损坏,集群中的某个节点将无法正常运行,从而导致集群功能受损。
StatefulSet 特点
StatefulSet 可以看作是 Deployment 的一个特殊变种,具有以下特性:
- StatefulSet 中的每个 Pod 都有稳定且唯一的网络标识,用于发现集群内的其他成员。例如,如果 StatefulSet 的名称是 “kafka”,那么第一个 Pod 的名称将是 “kafka-0”,第二个 Pod 的名称将是 “kafka-1”。
- StatefulSet 控制的 Pod 副本启动顺序是受控的,操作第 n 个 Pod 时,前一个 Pod 已经处于运行且准备就绪的状态。
- StatefulSet 中的 Pod 使用稳定的持久化存储卷(Persistent Volume,PV),在删除 Pod 时,默认不会删除相关的存储卷。
完整可用的 StatefulSet 通常由三个组件构成:StatefulSet、Headless Service 和 VolumeClaimTemplate。
稳定的网络标识
由 StatefulSet 创建的每个 Pod 都有一个从 0 开始的顺序索引,体现在 Pod 的名称、主机名和固定存储上。
StatefulSet 通常与 Headless Service 配合使用。如果解析 Headless Service 的 DNS 域名,将返回该 Service 对应的所有 Pod 的 Endpoint 列表。StatefulSet 在 Headless Service 的基础上为 StatefulSet 控制的每个 Pod 实例创建了一个 DNS 域名,格式为:$(podname).$(headless service name).$(namespace).svc.cluster.local。
当 StatefulSet 管理的 Pod 实例消失后,StatefulSet 会确保重新启动一个新的 Pod 实例,新实例具有与之前 Pod 完全一致的名称和主机名。
扩容 StatefulSet 时,将使用下一个尚未使用的顺序索引值创建一个新的 Pod 实例。缩容时,会先删除最高索引值的实例,每次只操作一个 Pod 实例,并且在存在不健康实例的情况下,不允许进行缩容操作。
稳定的专属储存
有状态的 Pod 的存储必须是持久的,并且与 Pod 解耦。StatefulSet 需要定义一个或多个卷声明模板,并将其绑定到 Pod 实例上。
在扩容 StatefulSet 时,会创建新的 Pod 实例以及与之关联的一个或多个持久卷声明。在缩容时,只会删除 Pod,而保留持久卷声明,在重新扩容后,新的 Pod 会与先前的持久卷绑定。
创建 STS
创建一个简单的应用,接收 POST 请求,并将请求中的 body 数据写入 /var/data/kubia.txt,在收到 GET 请求时,返回主机名和存储的数据:
root@ec837c407906:/# cat app.js
const http = require('http');
const os = require('os');
const fs = require('fs');
const dataFile = "/var/data/kubia.txt";
function fileExists(file) {
try {
fs.statSync(file);
return true;
} catch (e) {
return false;
}
}
var handler = function(request, response) {
if (request.method == 'POST') {
var file = fs.createWriteStream(dataFile);
file.on('open', function (fd) {
request.pipe(file);
console.log("New data has been received and stored.");
response.writeHead(200);
response.end("Data stored on pod " + os.hostname() + "\n");
});
} else {
var data = fileExists(dataFile) ? fs.readFileSync(dataFile, 'utf8') : "No data posted yet";
response.writeHead(200);
response.write("You've hit " + os.hostname() + "\n");
response.end("Data stored on this pod: " + data + "\n");
}
};
var www = http.createServer(handler);
www.listen(8080);首先,创建基于 NFS 的持久化存储卷:
[root@server4-master ~]$ cd /srv/pv/
[root@server4-master pv]$ mkdir pv001 pv002 pv003
[root@server4-master pv]$ echo "/srv/pv/pv001 *(rw,no_root_squash,sync)" >> /etc/exports
[root@server4-master pv]$ echo "/srv/pv/pv002 *(rw,no_root_squash,sync)" >> /etc/exports
[root@server4-master pv]$ echo "/srv/pv/pv003 *(rw,no_root_squash,sync)" >> /etc/exports
[root@server4-master pv]$ exportfs -a
[root@server4-master pv]$ showmount -e
Export list for server4-master:
/srv/pv/pv003 *
/srv/pv/pv002 *
/srv/pv/pv001 *
/srv/pv *
[root@server4-master pv]$ exportfs -v
/srv/pv <world>(sync,wdelay,hide,no_subtree_check,sec=sys,rw,secure,no_root_squash,no_all_squash)
/srv/pv/pv001 <world>(sync,wdelay,hide,no_subtree_check,sec=sys,rw,secure,no_root_squash,no_all_squash)
/srv/pv/pv002 <world>(sync,wdelay,hide,no_subtree_check,sec=sys,rw,secure,no_root_squash,no_all_squash)
/srv/pv/pv003 <world>(sync,wdelay,hide,no_subtree_check,sec=sys,rw,secure,no_root_squash,no_all_squash)可以使用 List 对象来定义一组 PV 资源,效果和使用 -- 分隔多个资源一样。设定 storageClassName 为 nfs:
[root@server4-master ~]$ vi pv-list.yaml
kind: List
apiVersion: v1
items:
- apiVersion: v1
kind: PersistentVolume
metadata:
name: pv001
spec:
capacity:
storage: 10Mi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: nfs
nfs:
path: /srv/pv/pv001
server: server4-master
- apiVersion: v1
kind: PersistentVolume
metadata:
name: pv002
spec:
capacity:
storage: 10Mi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: nfs
nfs:
path: /srv/pv/pv002
server: server4-master
- apiVersion: v1
kind: PersistentVolume
metadata:
name: pv003
spec:
capacity:
storage: 10Mi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: nfs
nfs:
path: /srv/pv/pv003
server: server4-master
[root@server4-master ~]$ kubectl create -f pv-list.yaml
persistentvolume/pv001 created
persistentvolume/pv002 created
persistentvolume/pv003 created
[root@server4-master ~]$ kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv001 10Mi RWO Retain Available nfs 8s
pv002 10Mi RWO Retain Available nfs 8s
pv003 10Mi RWO Retain Available nfs 8s在部署 StatefulSet 之前,还需要创建一个用于为有状态的 Pod 提供网络标识的 Headless Service,以实现 Pod 之间的互相发现:
[root@server4-master ~]$ vi kubia-svc-headless.yaml
apiVersion: v1
kind: Service
metadata:
name: kubia
spec:
clusterIP: None
selector:
app: kubia
ports:
- name: http
port: 80
[root@server4-master ~]$ kubectl create -f kubia-svc-headless.yaml
service/kubia created最后是 StatefulSet 的配置,其中 serviceName 和 template 字段是必需的:
[root@server4-master ~]$ vi kubia-st.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: kubia
spec:
serviceName: kubia
replicas: 2
selector:
matchLabels:
app: kubia
template:
metadata:
labels:
app: kubia
spec:
containers:
- name: kubia
image: luksa/kubia-pet
ports:
- name: http
containerPort: 8080
volumeMounts:
- mountPath: "/var/data"
name: data
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Mi
storageClassName: nfs通过一个名为 data 的 PVC 模板为每个 Pod 创建一个持久卷声明,在其中指定 storageClassName: nfs 来选择前面创建的 PV,这样 PVC 会自动与可用的 PV 相关联:
[root@server4-master ~]$ kubectl create -f kubia-st.yaml
statefulset.apps/kubia created
[root@server4-master ~]$ kubectl get all
NAME READY STATUS RESTARTS AGE
pod/kubia-0 1/1 Running 0 13s
pod/kubia-1 0/1 ContainerCreating 0 7s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 135d
service/kubia ClusterIP None <none> 80/TCP 29m
NAME READY AGE
statefulset.apps/kubia 1/2 13s
[root@server4-master ~]$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
data-kubia-0 Bound pv001 10Mi RWO nfs 42s
data-kubia-1 Bound pv002 10Mi RWO nfs 36s
[root@server4-master ~]$ kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv001 10Mi RWO Retain Bound default/data-kubia-0 nfs 64s
pv002 10Mi RWO Retain Bound default/data-kubia-1 nfs 64s
pv003 10Mi RWO Retain Available nfs 64s第二个 Pod 会在第一个 Pod 运行并处于就绪状态后创建。当所有 Pod 都就绪时,可以看到有 2 个 PV 已被新创建的 Pod 绑定。
测试 STS
由于服务处于 Headless 模式,无法通过服务访问服务本身。可以在节点上先运行代理,然后使用 curl 与 API 服务器与 Pod 进行通信:
[root@server4-master ~]$ kubectl proxy
Starting to serve on 127.0.0.1:8001
[root@server4-master ~]$ curl localhost:8001/api/v1/namespaces/default/pods/kubia-0/proxy/
You've hit kubia-0
Data stored on this pod: No data posted yet使用 POST 请求发送数据后,再使用 GET 请求查询数据:
[root@server4-master ~]$ curl -X POST -d "kubia-0" localhost:8001/api/v1/namespaces/default/pods/kubia-0/proxy/
Data stored on pod kubia-0
[root@server4-master ~]$ curl localhost:8001/api/v1/namespaces/default/pods/kubia-0/proxy/
You've hit kubia-0
Data stored on this pod: kubia-0
[root@server4-master ~]$ curl localhost:8001/api/v1/namespaces/default/pods/kubia-1/proxy/
You've hit kubia-1
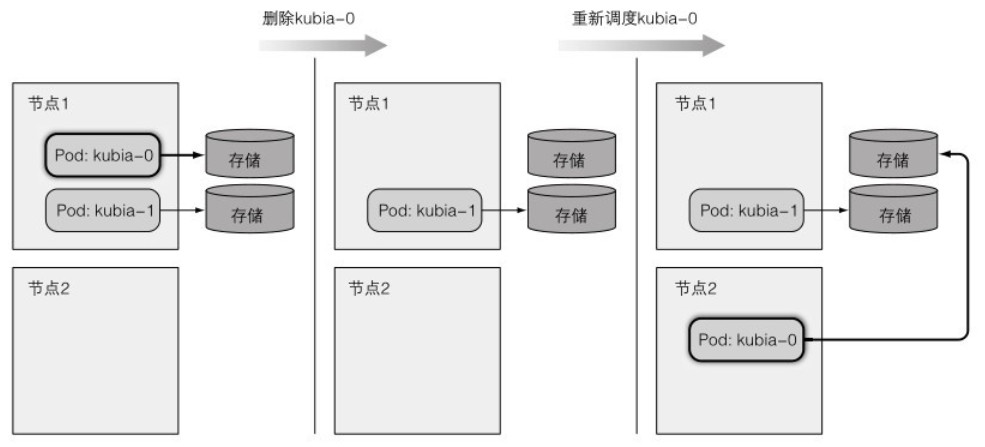
Data stored on this pod: No data posted yet手动删除 Pod 后,验证重新调度的 Pod 是否关联了相同的存储:
[root@server4-master ~]$ kubectl delete po kubia-0
pod "kubia-0" deleted
[root@server4-master ~]$ kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kubia-0 1/1 Running 0 18s 10.244.244.234 server6-node2 <none> <none>
kubia-1 1/1 Running 0 8m39s 10.244.244.233 server6-node2 <none> <none>删除后等待一段时间,kubia-0 在另一个节点上重建好了,用 curl 试试看数据是否还在:
[root@server4-master ~]$ curl localhost:8001/api/v1/namespaces/default/pods/kubia-0/proxy/
You've hit kubia-0
Data stored on this pod: kubia-0缩容一个 StatefulSet 只会删除对应的 Pod,持久卷声明将被卸载但保留。如下图所示:
发现节点
集群中伙伴节点能够彼此发现是非常重要的需求,这样才能找到集群中的其他成员。虽然可以通过 API 服务器进行通信来获取这些信息,但这与 Kubernetes 的设计理念不符。因此,Kubernetes 通过一个无头服务(headless Service)来创建 SRV 记录,从而指向 Pod 的主机名。
可以通过查询 DNS 记录中的 SRV 记录来获取这些信息。SRV 记录用于指向提供服务的服务器的主机和端口号:
[root@server4-master ~]$ kubectl run -it srvlookup --image=tutum/dnsutils --rm --restart=Never -- dig SRV kubia.default.svc.cluster.local
; <<>> DiG 9.9.5-3ubuntu0.2-Ubuntu <<>> SRV kubia.default.svc.cluster.local
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 27077
;; flags: qr aa rd; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 3
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;kubia.default.svc.cluster.local. IN SRV
;; ANSWER SECTION:
kubia.default.svc.cluster.local. 30 IN SRV 0 50 80 kubia-1.kubia.default.svc.cluster.local.
kubia.default.svc.cluster.local. 30 IN SRV 0 50 80 kubia-0.kubia.default.svc.cluster.local.
;; ADDITIONAL SECTION:
kubia-0.kubia.default.svc.cluster.local. 30 IN A 10.244.244.234
kubia-1.kubia.default.svc.cluster.local. 30 IN A 10.244.244.233
;; Query time: 1 msec
;; SERVER: 10.96.0.10#53(10.96.0.10)
;; WHEN: Fri Mar 18 15:40:53 UTC 2022
;; MSG SIZE rcvd: 350通过创建一个临时 Pod 并运行 dig 命令,可以看到 ANSWER SECTION 显示了两条指向后台无头服务的 SRV 记录。在 ADDITIONAL SECTION 中,每个 Pod 都拥有一条独立的记录。当一个 Pod 需要获取 StatefulSet 中其他 Pod 的列表时,只需要触发一次 SRV DNS 查询即可。
滚动升级
StatefulSet 的升级方式与 Deployment 相同。推荐先修改配置文件中的镜像或参数,然后使用 kubectl apply -f 命令进行更新:
[root@server4-master ~]$ vi kubia-st.yaml
...
replicas: 3
...
image: luksa/kubia-pet-peers
...
[root@server4-master ~]$ kubectl apply -f kubia-st.yaml
statefulset.apps/kubia configured
[root@server4-master ~]$ kubectl get po
NAME READY STATUS RESTARTS AGE
dnsutils 1/1 Running 0 43m
kubia-0 1/1 Terminating 0 5h10m
kubia-1 1/1 Running 0 32s
kubia-2 1/1 Running 0 77s测试集群数据
当所有的 Pod 启动后,可以测试数据存储是否按预期工作。首先将 Service 修改为非无头模式,然后向集群发送一些请求:
[root@server4-master ~]$ vi kubia-svc-peer.yaml
apiVersion: v1
kind: Service
metadata:
name: kubia-public
spec:
selector:
app: kubia
ports:
- name: http
port: 80
targetPort: 8080
[root@server4-master ~]$ kubectl apply -f kubia-svc-peer.yaml
service/kubia-public created
[root@k8s-master 2]$ curl -X POST -d "11:58:04" localhost:8001/api/v1/namespaces/default/services/kubia-public/proxy/
Data stored on pod kubia-1
[root@k8s-master 2]$ curl -X POST -d "11:58:04" localhost:8001/api/v1/namespaces/default/services/kubia-public/proxy/
Data stored on pod kubia-1
[root@k8s-master 2]$ curl -X POST -d "11:58:04" localhost:8001/api/v1/namespaces/default/services/kubia-public/proxy/
Data stored on pod kubia-2现在三个 Pod 中都有数据了,可以测试从服务中读取数据:
[root@k8s-master 2]$ curl localhost:8001/api/v1/namespaces/default/services/kubia-public/proxy/
You've hit kubia-2
Data stored in the cluster:
- kubia-2.kubia.default.svc.cluster.local: 11:58:04
- kubia-1.kubia.default.svc.cluster.local: 11:58:04
- kubia-0.kubia.default.svc.cluster.local: kubia-0通过集群中的任意一个节点都能够获取到所有伙伴节点的数据,然后收集它们的数据。
处理节点失效
对于一个有状态的 Pod,必须确保在创建替代 Pod 之前不再运行。当一个节点突然失效时,Kubernetes 并不知道节点的状态,也不知道 Pod 是否还在运行、是否还存在、是否能够被客户端访问,或者是 Kubelet 停止了上报节点状态。只有在 StatefulSet 明确知道一个 Pod 不再运行后,才会采取相应的措施。这个信息通常由管理员删除 Pod 或整个节点来明确指定。
可以模拟一次节点故障。首先,查看当前的运行状态:
[root@server4-master ~]$ kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE
kubia-0 1/1 Running 0 29m 10.244.191.226 server5-node1
kubia-1 1/1 Running 0 30m 10.244.191.225 server5-node1
kubia-2 1/1 Running 0 12s 10.244.191.227 server5-node1 发现所有的 Pod 都运行在 node1 节点上。然后,断开 node1 的网络连接,并等待 2 分钟后查询节点信息:
[root@server4-master ~]$ kubectl get node
NAME STATUS ROLES AGE VERSION
server4-master Ready control-plane,master 135d v1.22.3
server5-node1 NotReady <none> 135d v1.22.3
server6-node2 Ready <none> 135d v1.22.3
[root@server4-master ~]$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
kubia-0 1/1 Running 0 119s 10.244.191.228 server5-node1
kubia-1 1/1 Running 0 38m 10.244.191.225 server5-node1
kubia-2 1/1 Running 0 8m10s 10.244.191.227 server5-node1 可以看到 node 已变为 NotReady 状态,但 pod 状态没有更新。如果运行 delete 命令,因为节点上 kubelet 无法接收到命令,所以 pod 的状态会一直显示 Terminating。
再过一段时间,pod 的状态会变成 Unknown。有一个配置可以调整未知状态持续多久,pod 自动从节点上驱除。
假如节点重连上了,删除命令会被正确执行并在空闲节点上新建 pod。如果节点永远消失了,只能通过强制删除 pod 来解决。通过删除命令加上 --force 和 grace-period 0 两个参数来强制删除:
[root@server4-master ~]$ kubectl delete po kubia-0 --force --grace-period 0
warning: Immediate deletion does not wait for confirmation that the running resource has been terminated. The resource may continue to run on the cluster indefinitely.
pod "kubia-0" force deleted
[root@server4-master ~]$ kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE
kubia-0 1/1 Running 0 19s 10.244.244.245 server6-node2
kubia-1 1/1 Running 0 39m 10.244.191.225 server5-node1
kubia-2 1/1 Running 0 9m7s 10.244.191.227 server5-node1 pod 强制删除后会在 node2 节点上新建,一般只有确认节点永远不能用的情况下才使用强制删除。
假如不强制删除,而把断开网络的 node1 节点重新连上,pod 的状态会从 Unknown 变为正常运行。
DaemonSet
下面简称 DS。与 RS 相比,DS 多了一个 nodeSelector 选择器,DS 依赖节点标签选择器来控制。
定义
使用 DS 来设置在集群中每个节点固定运行一个 pod,通常用来部署系统服务,比如用来收集日志或者做资源监控。
也可以通过 nodeSelector 选择器来选择一组节点作为部署节点,而不是默认的所有节点。
如果被选择器选择的节点被设置为不可调度,DS 依然会绕过调度器将 pod 部署到这种节点上。
创建 DS
首先给一个节点打上标签 disk='ssd' :
[root@server4-master ~]$ kubectl label node server5-node1 disk='ssd'
node/server5-node1 labeled然后建立 YAML 配置文件并启动:
[root@server4-master ~]$ vi kubia-ds.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: ds-ssd
spec:
selector:
matchExpressions:
- key: app
operator: In
values:
- kubia-ssd
template:
metadata:
labels:
app: kubia-ssd
spec:
nodeSelector:
disk: ssd
containers:
- name: kubia
image: luksa/kubia
[root@server4-master ~]$ kubectl create -f kubia-ds.yaml
daemonset.apps/ds-ssd createdDS 还可以配置更新机制,相关配置定义在 spec.updateStrategy 字段,方式为 RollingUpdate(滚动更新)或 OnDelete(删除再更新)。回滚操作同样支持。
验证
将 server6-node2 也打上 ssd 标签后再查看信息:
[root@server4-master ~]$ kubectl label node server6-node2 disk='ssd'
[root@server4-master ~]$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
ds-ssd-drb2z 1/1 Running 0 4m19s 10.244.191.199 server5-node1
ds-ssd-f6cwh 1/1 Running 0 23s 10.244.244.199 server6-node2 去除节点标签后运行在其上的 pod 会立即删除:
[root@server4-master ~]$ kubectl label node server6-node2 disk-
[root@server4-master ~]$ kubectl label node server5-node1 disk-
[root@server4-master ~]$ kubectl get ds
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
ds-ssd 0 0 0 0 0 disk=ssd 7m52sJob
Job 用于执行一个可完成的任务,进程终止之后不会再次启动。
在发生节点故障时,该节点上由 Job 管理的 pod 将重新安排到其他节点运行。如果节点本身异常退出(返回错误退出代码时),可以将 Job 配置为重新启动容器,由 Job 管理的 pod 会一直被重新安排直到任务完成为止。
Job 使用 API 为 batch/v1。需要明确地将重启策略设置为 OnFailure 或 Never,防止容器在完成任务时重新启动。
创建 Job
这里调用了一个运行 120 秒的进程然后退出。指定 restartPolicy 属性为 OnFailure(默认为 Always):
[root@server4-master ~]$ vi kubia-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: batch-job
spec:
template:
metadata:
labels:
app: batch-job
spec:
restartPolicy: OnFailure
containers:
- name: main
image: luksa/batch-job
[root@server4-master ~]$ kubectl create -f kubia-job.yaml当 Job 任务完成后,状态显示为 Completed:
[root@server4-master ~]$ kubectl get jobs
NAME COMPLETIONS DURATION AGE
batch-job 1/1 119s 2m59s
[root@server4-master ~]$ kubectl get pod
NAME READY STATUS RESTARTS AGE
batch-job--1-2ddkr 0/1 Completed 0 3m10s出于查询日志的需求,完成任务的 pod 不会自动删除,可以通过删除创建的 Job 来一同删除。
多次运行
可以在 Job 中配置创建多个 pod 实例,设置 completions 和 parallelism 属性来以并行或串行方式运行。
顺序运行用于一个 Job 运行多次的场景,例如设置顺序运行五个 pod,每个 pod 成功完成后工作才结束:
[root@server4-master ~]$ vi kubia-job.yaml
spec:
completions: 5
[root@server4-master ~]$ kubectl create -f kubia-job.yaml
[root@server4-master ~]$ kubectl get jobs
NAME COMPLETIONS DURATION AGE
batch-job 0/5 12s 12s设置并行运行需要多加一个 parallelism 参数设置并行启动 pod 数目:
[root@server4-master ~]$ vi kubia-job.yaml
spec:
completions: 5
parallelism: 3
[root@server4-master ~]$ kubectl delete job batch-job
[root@server4-master ~]$ kubectl create -f kubia-job.yaml
[root@server4-master ~]$ kubectl get po
NAME READY STATUS RESTARTS AGE
batch-job--1-5ghsj 1/1 Running 0 39s
batch-job--1-mctcz 1/1 Running 0 39s
batch-job--1-znpbq 1/1 Running 0 39sJob 的并行任务数同样可以通过 scale 命令来修改。
限制条件
可以通过 activeDeadlineSeconds 属性来限制 pod 的运行时间。如果超时没完成,系统会尝试终止 pod 并标记失败。
还能配置 Job 被标记为失败前重试的次数,通过 spec.backoffLimit 字段,默认为 6 次。
CronJob
可以创建 CronJob 资源来通过 cron 格式时间表,设置一个定时运行的 Job 任务。
下面简称 CJ。K8s 通过 CJ 中配置的 Job 模板创建 Job 资源。
创建 CJ
创建一个每十五分钟运行一次的 Job:
[root@server4-master ~]$ vi kubia-cj.yaml
apiVersion: batch/v1
kind: CronJob
metadata:
name: 15job
spec:
schedule: "0,15,30,45 * * * *"
jobTemplate:
spec:
template:
metadata:
labels:
app: 15job
spec:
restartPolicy: OnFailure
containers:
- name: main
image: luksa/batch-job
[root@server4-master ~]$ kubectl create -f kubia-cj.yaml
[root@server4-master ~]$ kubectl get cj
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
15job 0,15,30,45 * * * * False 0 <none> 16s其中 schedule 段五个设置分别是:分钟 小时 每月日期 月 星期
超时设置
可以通过 startingDeadlineSeconds 字段来设置预定运行超时时间,例如不能超过预定时间 15 秒后运行:
[root@server4-master ~]$ vi kubia-cj.yaml
spec:
startingDeadlineSeconds: 15不管任何原因,时间超过了 15 秒而没启动任务,任务将不会运行并显示失败。
其他设置
其他一些 spec 字段可嵌套使用字段:
-
concurrencyPolicy:并发执行策略,用于定义前一次作业运行尚未完成时是否以及如何运行后一次的作业。可选值为 Allow、Forbid 或 Replace。
-
failedJobHistoryLimit:为失败的任务执行保留的历史记录数,默认为 1。
-
successfulJobsHistoryLimit:为成功的任务执行保留的历史记录数,默认为 3。
-
startingDeadlineSeconds:设置超时时间,超时未完成任务会被记入错误历史记录。
-
suspend:是否挂起后续的任务执行,默认为 false,对运行中的作业不会产生影响。